
The Ultimate Guide to S3 Costs

CTO and Co-founder
In a previous article, we introduced Amazon S3, an affordable, cloud-based, enterprise-class storage solution. However, when organizations regularly store, upload, access, and transfer large volumes of data to S3, the costs can all rack up to tens of thousands of dollars.
To know how to optimize S3 costs, you first need to understand the types of expenses that come with it. This is what we will cover here today.
Types of S3 Costs
The total cost of using S3 can include:
- The actual storage cost
- Data access costs including reading, writing, listing, querying or downloading data
- Data transfer costs including replication
- S3 management costs
Before we cover these, let’s talk about the different S3 storage classes.
What Are The S3 Storage Classes?
When uploading one or more files to S3, you can choose a storage class for the files. Among other things, the storage class tells S3 how the file should be stored, where it will be stored, and what should be the costs of storing and accessing the data. Here are the different types of S3 storage classes:
- S3 Standard
- S3 Intelligent Tiering
- S3 Standard Infrequent Access (S3 Standard-IA)
- S3 One Zone Infrequent Access (S3 One Zone-IA)
- S3 Glacier
- S3 Glacier Deep Archive
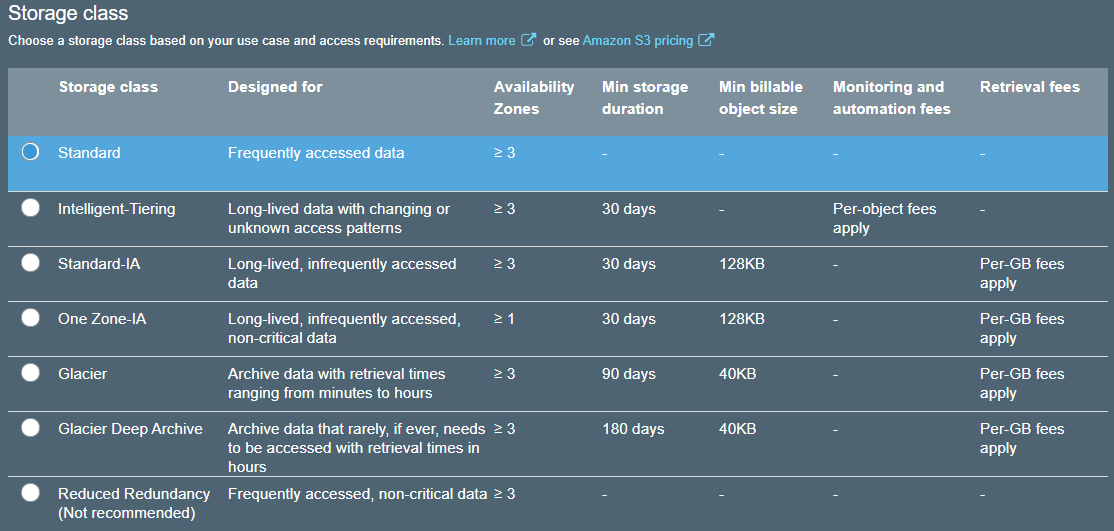
It’s possible to store objects with different storage classes in the same bucket. You can also create S3 lifecycle policies to transition objects from one storage class to another automatically.
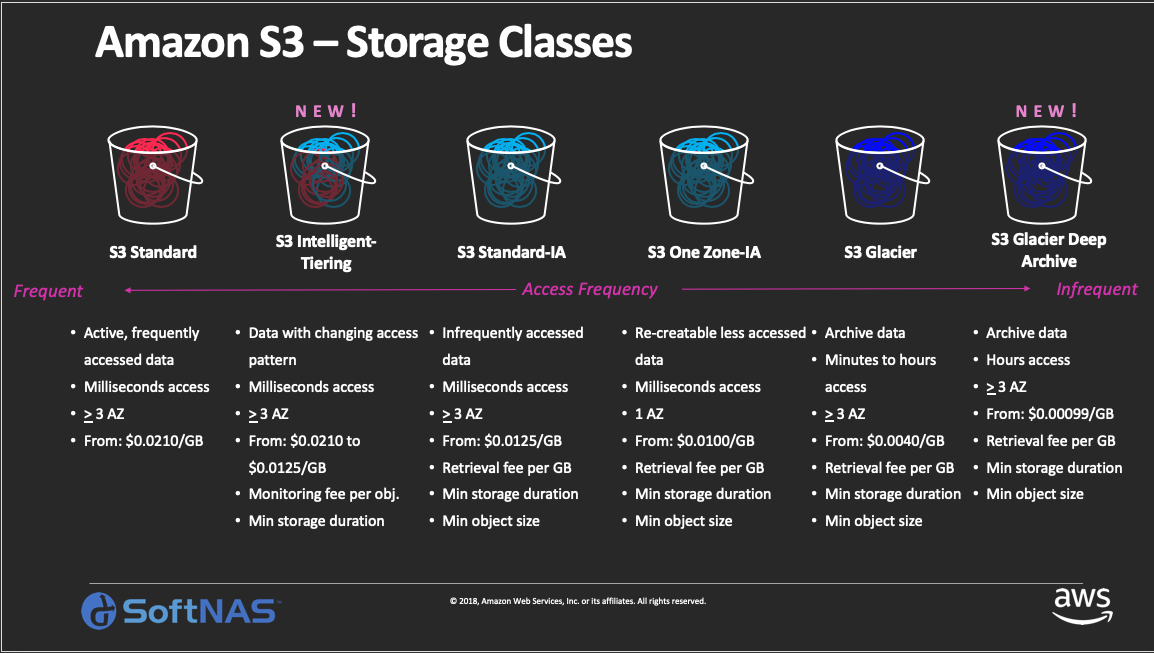
S3 Standard
S3 Standard is the default storage class for S3 and offers high durability, high availability, low latency, and high throughput. This is suitable for applications that need frequent access to data. Some examples of such applications can be online gaming, big data workloads, or SaaS products.
S3 Intelligent Tiering
The S3 Intelligent Tiering is designed to optimize S3 storage costs without sacrificing the durability, availability, low latency, and throughput of the S3 Standard. With Intelligent Tiering, objects are stored in two access tiers: one for frequent access, the other for infrequent access. The infrequent access tier costs less than the frequent access tier. S3 automatically monitors access patterns for objects and dynamically moves objects that have not been accessed for 30 days in a row to the infrequent access tier. If an object is accessed again, it’s moved back to the frequent access timer. With this model, users only pay for the monitoring and automation fee for the objects. There’s no cost for moving data between the two tiers.
S3 Standard Infrequent Access (S3 Standard-IA)
S3 Standard-IA storage class is best suited for data that are not accessed frequently but need the same level of low latency when accessed. S3 Standard-IA offers the same high durability, high availability, high throughput, and low latency as Standard S3, but has lower storage and retrieval costs.
S3 One Zone Infrequent Access (S3 One Zone-IA)
S3 One Zone-IA has the same high durability, high throughput, and low latency of S3 Standard and S3 Standard-IA storage classes, but has a lower availability rate (99.5%). S3 One Zone-IA files are saved in one Availability Zone (AZ) only. As a result of this lower resiliency, S3 One Zone-IA costs 20% less than S3 Standard-IA.
S3 Glacier
S3 Glacier is mainly designed for data archival workloads. Many organizations need long-term data storage for regulatory compliance. This data may not be operationally active but needs archival storage with competitive pricing. S3 Glacier is the answer to that.
AWS customers can either directly upload their legacy data to S3 Glacier, or create S3 lifecycle policies to transition data to Glacier. The time for data retrieval from Glacier can range from a few minutes to twelve hours, depending on the tier used.
S3 Glacier Deep Archive
S3 Glacier Deep Archive is the lowest-cost storage class in S3. It’s also designed for data archival scenarios, but unlike S3 Glacier, its retrieval time is within twelve hours, whereas S3 Glacier allows you to urgently retrieve data within minutes using expedited retrieval. S3 Glacier Deep Archive can be an ideal data retention solution for enterprises that need to access archived data only once or twice a year.
What Is S3 Lifecycle Policy?
S3 lifecycle policies can help optimize S3 storage costs and object management. Lifecycle policies do this by defining actions that are to be performed on a bucket’s contents after a configurable period has elapsed. For example, a lifecycle policy can transition all objects from a bucket’s S3 Standard class to S3 Standard-IA six months after uploading. Another policy can transition Standard S3-IA class files to S3 Glacier after another six months.
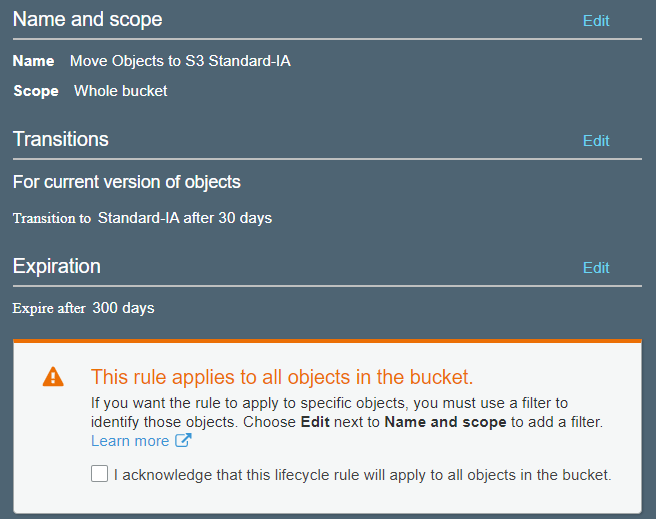
Now that you know about S3 storage classes let’s talk about all the costs associated with S3. Different AWS regions have different S3 rates; for the sake of simplicity, we will base our examples on us-east-1 (North Virginia) only. However, the method of calculating S3 costs remains the same for any region. You can also visit the S3 pricing page to see the pricing for other regions.
What are S3 Storage Costs?
Here is the cost of storing data in different S3 storage classes in the us-east-1 region:

Using these figures, let’s say you want to store 100 TB of data in the S3 us-east-region.
If you use the S3 Standard storage class, the cost will be:
((50 x 1024) x $0.023) + ((50 x 1024) x $0.022) = $2,304 per month
Now, let’s say the business thinks that the data doesn’t need to be accessed frequently. If you store it in the S3 Standard – Infrequent Access class, the storage cost will be:
(100 x 1024) x $0.0125 = $1,280 per month.
What are S3 Operations Costs?
Any request for an S3 operation will send an API call to the S3 endpoint. These requests can be from the console when browsing through a bucket, uploading a file with the CLI, or retrieving data using an SDK. S3 categorizes these requests into the following types of API operations:
- LIST
- GET
- PUT
- COPY
- POST
- SELECT
- DELETE (doesn’t cost anything)
- CANCEL (doesn’t cost anything)
- Data Retrieval
- Lifecycle Change
Most S3 operations usually cost money. An S3 operation’s cost depends on the API call and the number of objects it affects. The table below shows these prices for the us-east-1 region:
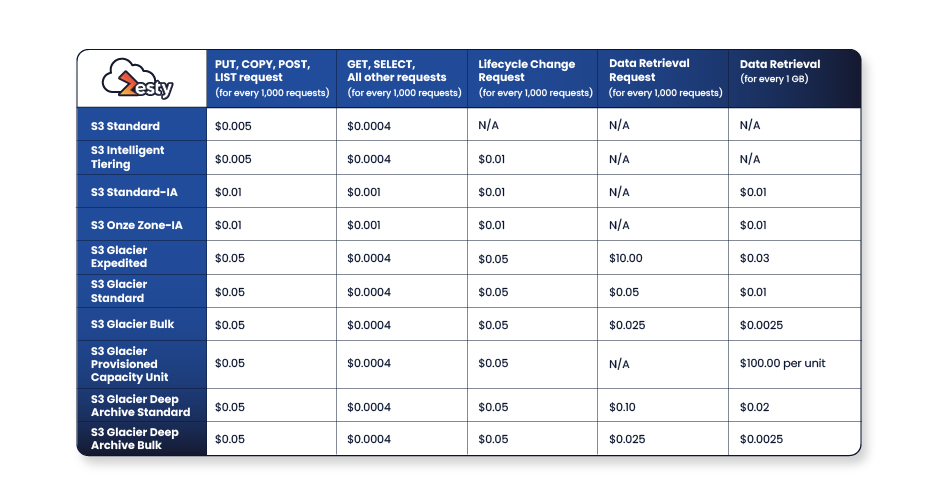
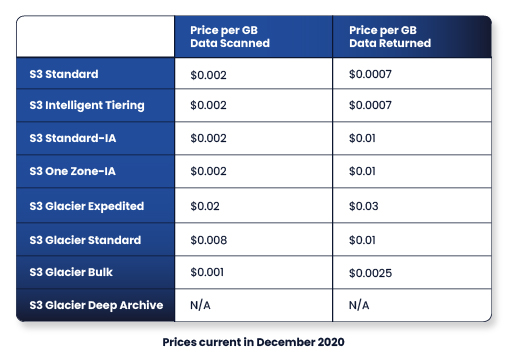
Another data operation is S3 Select. With this feature, users and applications don’t need to download entire files from S3 to filter and extract data. Instead, SQL SELECT statements can be run on an S3 object to pull out just the data needed. This approach dramatically reduces data retrieval costs. The table below shows pricing for S3 Select and S3 Glacier Select in the us-east-region:
What are S3 Data Transfer Costs?
S3 data transfer can be categorized into five scenarios:
- Data transfer into S3 from the Internet
- Data transfer from S3 to the Internet
- Data transfer from S3 to Amazon EC2 instances in the same region
- Data transfer from S3 to Amazon CloudFront
- Data transfer from S3 to other AWS regions
Of these, it doesn’t cost anything to transfer data
- Into S3 from the Internet
- From S3 to Amazon EC2 instances in the same region
- From S3 to Amazon CloudFront
To transfer data from S3 to the Internet, us-east-1 regions has a diminishing pricing structure like this:
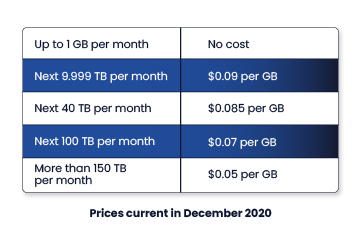
Let’s say you are uploading 500 GB worth of files over the Internet from an on-premise application to an S3 bucket every month. The cost for this upload will be: 500 x $0.09 = $45 per month.
When transferring data between S3 regions, the cost can vary between $0.02 and $0.1105 per GB. For example, let’s say you have 100 TBs of data stored in the S3 in the AWS Singapore region. You want to transfer this data to the Sydney region. The cost of this transfer will be 100 x 1024 x $0.09. = $9,216.
Enterprises can also take advantage of S3 Transfer Acceleration for faster data transfer to S3. With S3 Transfer Acceleration, clients send data over the Internet to an Amazon CloudFront edge location instead of an S3 bucket. The AWS edge locations are distributed across different geographic regions and therefore can optimize network transfer distances. Once CloudFront receives the data, it sends it to the S3 bucket using an optimal network path. As you saw before, there’s no cost to send data from CloudFront to S3.
Transfer Acceleration can be an ideal solution when you have a single AWS region footprint and your data sources are spread throughout the world. The cost of Transfer Acceleration in the us-east-1 region is shown here:
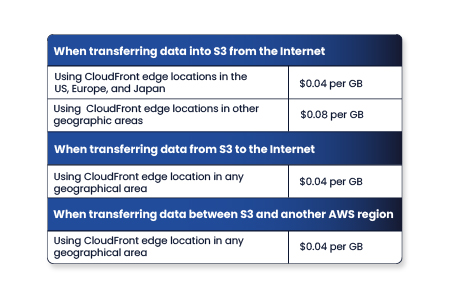
If we go back to our example of transferring 500 GB data from an on-premise application to S3 every month, that cost can be optimized using Transfer Acceleration. Assuming our edge location is in the US, Europe, or Japan, the price will be 500 x 0.04 = $20 per month.
What Are S3 Management Costs?
S3 has a few options for managing buckets and objects:


S3 Batch Operations
S3 Batch Operations is an AWS-managed service optimized for large-scale S3 operations. Typically these large-scale operations are meant to happen across millions or even billions of objects and petabytes of data. For example, copying billions of objects between buckets or tagging billions of objects in one go are good candidates for S3 Batch Operations. The batch operations are performed by user-created jobs.
In the us-east-1 region:
- Each Batch Operation job costs $0.025
- Every 1 million object operations cost $1.00
- Also, there are costs associated with the actual S3 operation
We have already talked about lifecycle management. Let’s talk about the other ones.
S3 Inventory
S3 Inventory is used to audit the encryption and replication status of files stored in S3. It can be useful for regulatory compliance reporting. The inventory can be enabled to run daily or weekly, and the audit reports can be saved in a separate bucket. Once generated, the reports can be queried with Amazon Athena or mapped as tables in Amazon Redshift Spectrum.
In the us-east-1 region, the S3 Inventory task costs $0.0025 per millions of objects listed in the reports. This may seem trivial as even some large enterprises don’t store millions of S3 objects. However, there are S3 storage costs for the reports, and there are costs of accessing those reports from Amazon Athena or Redshift.
S3 Analytics Storage Class Analysis
The S3 Analytics Storage Class Analysis feature allows you to let S3 analyze your S3 objects’ access patterns. The analysis result can help you make better decisions about transitioning files from Standard to Standard-IA class.
Storage Class Analysis can monitor the access patterns of all your S3 objects, S3 objects with a common prefix, or S3 objects with a standard set of tags. Once the analysis process runs over a period of time, the resulting reports can help you design your object lifecycle policies.
In us-east-1, storage analysis costs $0.10 per million objects monitored per month. Again, this is almost negligible if your organization is scanning only hundreds or even hundreds of thousands of objects. Storage analysis reports are visible from the S3 console, but you can also save those as CSV files in a bucket.
S3 Object Tagging
Object Tagging allows you to add meaningful “tags” to your S3 files. Tags can be useful for classifying data.
In the us-east-1 region, object tagging costs $0.01 per 10,000 tags per month. To see how it works, let’s say you are uploading 200,000 IoT data files per day in an S3 bucket. One of the tasks after the upload is identifying each file with a device ID number. If you are using tagging to do so, the cost (over a 30-day month) will be:
((200,000 x 30) / 10,000) x $0.01 = $6
S3 Replication
S3 Replication is used for automatic, asynchronous copying of objects between S3 buckets. The buckets can be within the same AWS region or different regions; they can be in the same AWS account or different ones.
Replication may be necessary to satisfy certain conditions like legal compliance and data sovereignty laws, data aggregation, synched non-production environment or minimizing access latency.
Amazon also offers S3 Replication Time Control (S3 RTC) for workloads that need guaranteed S3 replication within a short period of time. S3 RTC replicates 99.99% of S3 objects to a destination bucket within 15 minutes of being uploaded to the source.
Here is a list of S3 replication cost components:
Final Thoughts
Now that you know all the costs associated with S3, you are better equipped to look at your organization’s S3 footprint and start thinking about cost optimization opportunities. If you are trying to estimate S3 costs for the future, you can use the AWS Pricing Calculator for creating realistic estimates. In the third and final article of this series, we will discuss a few ways to optimize S3 costs.

Related Articles
-
 How Multi-Dimensional Autoscaling fixes Kubernetes resource waste
How Multi-Dimensional Autoscaling fixes Kubernetes resource waste
May 18, 2026 -
 Key takeaways from the MarketsandMarkets Cloud FinOps report
Key takeaways from the MarketsandMarkets Cloud FinOps report
February 5, 2026 -
 How Daily Micro-Savings Plans redefine cloud savings
How Daily Micro-Savings Plans redefine cloud savings
October 27, 2025 -
 Zesty now supports In-Place Pod Resizing for Seamless, Real-Time Vertical Scaling
Zesty now supports In-Place Pod Resizing for Seamless, Real-Time Vertical Scaling
July 30, 2025 -
 Kubernetes Updates – June
Kubernetes Updates – June
July 16, 2025



