
Storage for Kubernetes: Getting to the Bottom of Persistent Volumes

So if PVs can be detached from K8 pods to enable performance flexibility and data persistence, all our problems are solved, right?
Well, not exactly. PVs are not 100% reliable in all scenarios, especially when scaling and elasticity are required.
An auto-scaler for PVs is available using a Container Storage Interface, however, this has some limitations when applied to EBS volumes. First and foremost, volumes can be extended only once every six hours. This entails you cannot scale on-demand, if application usage exceeds the capacity for the volume. While it’s possible to launch another volume to extend your filesystem further, once you’ve extended your PV, it can’t be shrunk back down again. This can be costly if your K8s cluster experiences a temporary fluctuation in demand, where you will be charged the price from the peak, no matter how fleeting it was, even after usage returns to a normal state.
However, another problem arguably more concerning, is that PVs are prone to fill up when there’s a high level of data ingestion. Projects that involve large amounts of data, such as ETLs, machine learning pipelines, and databases are all examples that cause data spikes. In this situation, the available capacity of PVs can be exceeded, potentially causing the application to crash as a result. 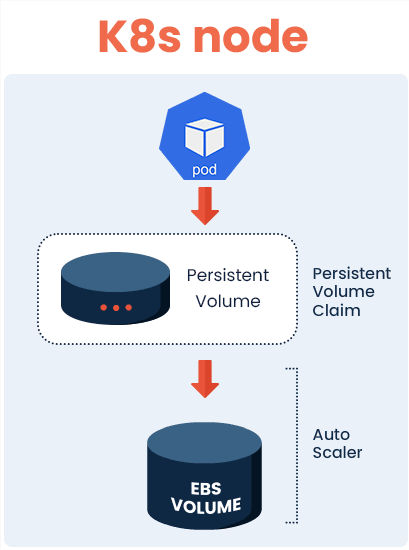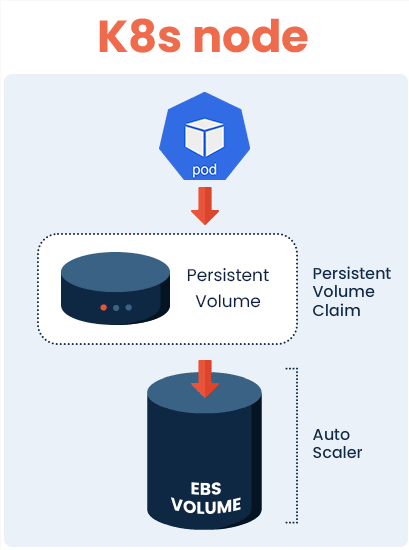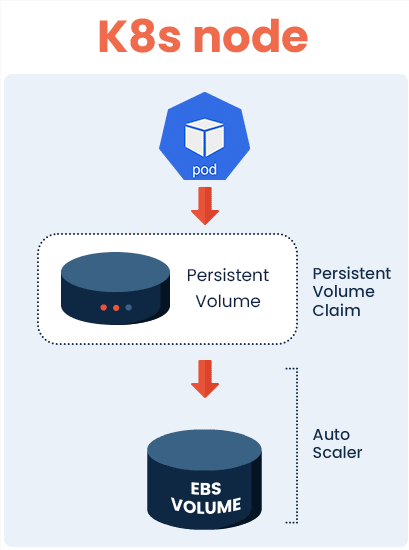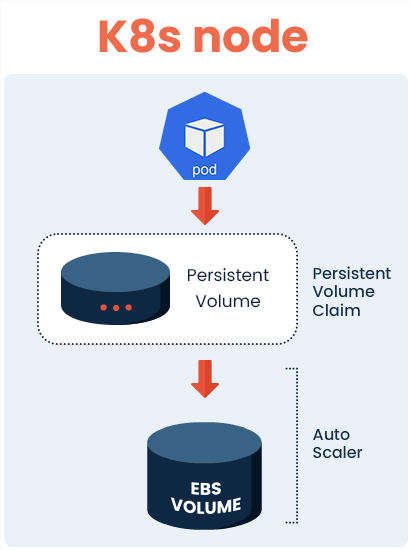
Related Articles
-
 Optimizing Storage for AI Workloads
Optimizing Storage for AI Workloads
December 19, 2023 -
 How to Improve Stateful Deployments on Kubernetes
How to Improve Stateful Deployments on Kubernetes
December 11, 2023 -
 Improving Storage Efficiency for Solr & Elasticsearch
Improving Storage Efficiency for Solr & Elasticsearch
November 6, 2023 -
 Finding the Right Balance Between Cost and Performance in Your Public Cloud
Finding the Right Balance Between Cost and Performance in Your Public Cloud
July 16, 2023 -
 Ensuring Optimal Resource Utilization for Data Streaming Workloads
Ensuring Optimal Resource Utilization for Data Streaming Workloads
July 13, 2023




