Ensuring Optimal Resource Utilization for Data Streaming Workloads

In a typical data streaming scenario, data streams in various sizes and formats are poured into a “lake” or receiver. The receiver can be a database, data warehouse, S3 bucket, service, app, or message broker, which we will focus on today.
In contrast to messaging queues, a message broker in the context of data streaming, delivers data to multiple destinations simultaneously. It’s also designed to handle high throughputs and a large number of connections, making it a popular choice for ingesting high-velocity data and event streaming compared to databases.
Data lands within the message broker’s memory, and when possible, data offloads to the non-volatile storage – local disk.
A common problem with data streaming is handling the unexpected. What does it mean?
Data streaming is highly characterized by burst activity, where there are distinct peaks and troughs in the volume of data transfer.
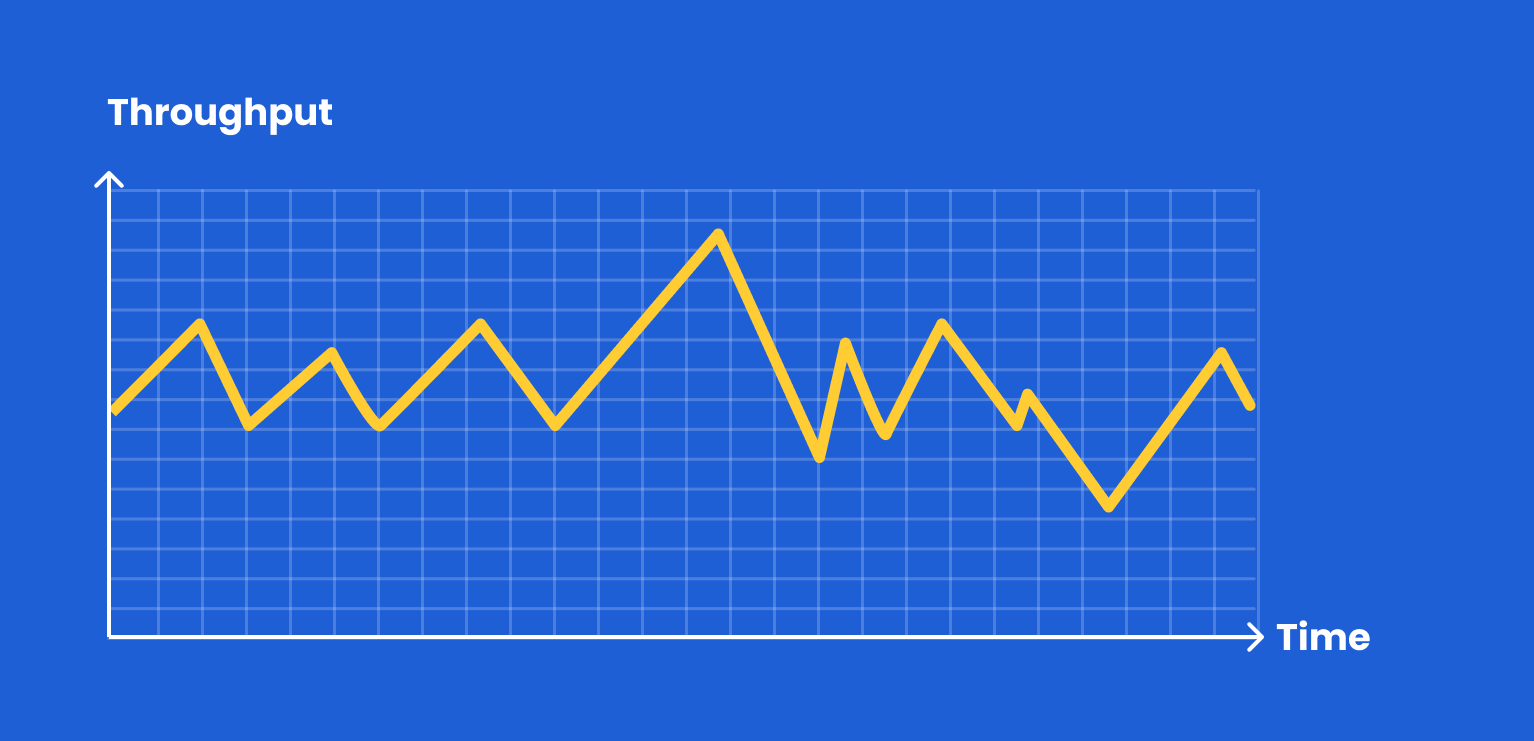
The main cost challenge of bursting workloads is that storage will often be provisioned (and purchased) based on the 1% peak time.
Let’s use an example to demonstrate it better –
In most e-commerce companies, the predictable busiest days are the 1st and the 28th day of each month. During those days, traffic increases by 300%.
- More traffic means more user events.
- More events mean more streamed data being ingested by the streaming platform.
- The usual event traffic is 1 TB worth of new events per day. But during peak times, traffic can triple, and therefore, it requires a static amount of 3Tb of available storage per day.
- This static allocation for just two days of high volume in a month will require 90Tb (3TB x 30 days) worth of storage instead of 34 Tb (1TB x 28 days + 3TB x 2 days).
- Keep in mind that this is the case on the presumption that there is just 1-day data retention. If more days are needed due to slow processing, it can quickly grow to 180Tb, 270TB, and so on.
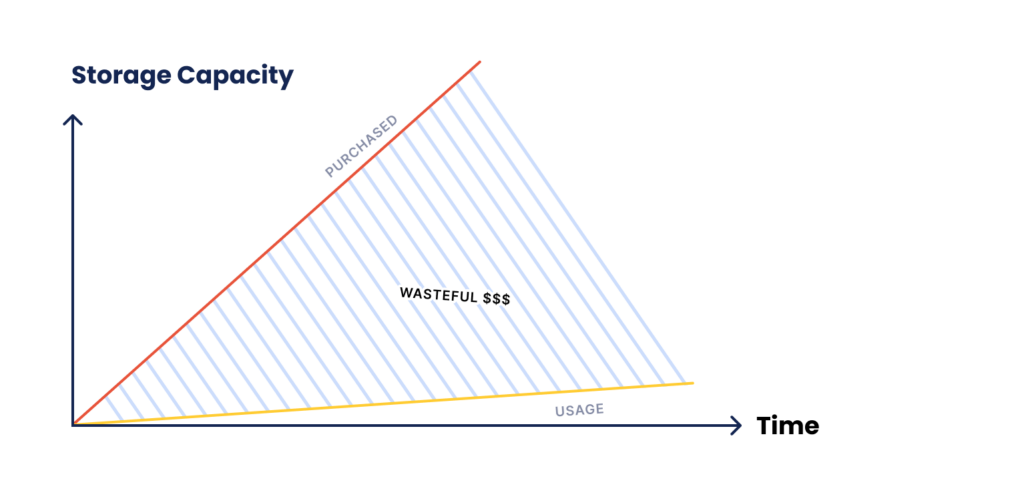
The ideal solution is to have “dynamic” storage that scales up when needed and down when it’s not. In the following article, you will learn how to achieve this capability, reducing provisioned storage when not needed and scaling up when it is. With the help of storage tiering and dynamic volume resizing, this ability optimizes costs significantly.
Having your streaming platform deployed and run on Kubernetes would be the foundation for enabling the steps provided below and, more importantly, would immediately reduce maintenance and management overhead, with solutions like Karpenter which also contributes to a lower TCO.
One of the biggest strengths of Kubernetes is its ability to abstract software and hardware
An example of such an abstraction would be the operating system and its filesystems with the server’s attached disks. When operating in a bare metal environment, there is a strong coupling between the physical disks and the OS file systems, making it hard to execute runtime changes. The abstraction of the operating system and attached storage therefore helps to support the ongoing availability of the app, making the streaming platform more resilient against disruptions.
Why and how is this helpful for cost savings? One of the significant challenges that Kubernetes solved was the strong coupling between the app, operating system, compute, and storage. When working with bare metal, any minor change to the storage layer can cause operating system disruption due to the natural coupling between the filesystem and the attached disks.
You would need a cloud-native streaming platform that can run natively on Kubernetes to benefit from this application’s availability. Both Apache Kafka and RabbitMQ support non-native Kubernetes deployments through different flavors and Memphis.dev which runs natively on any cloud and any Kubernetes environment, including K3.
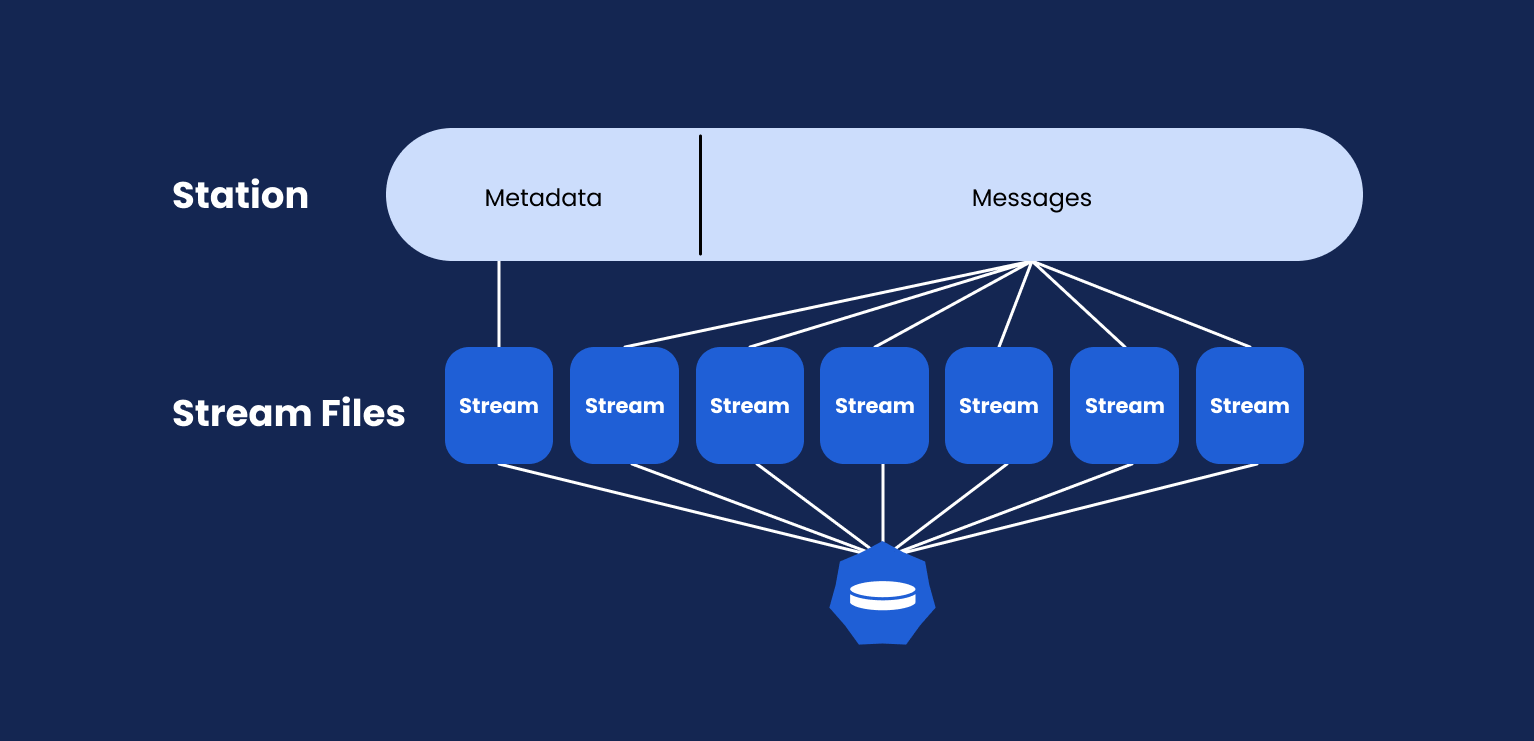
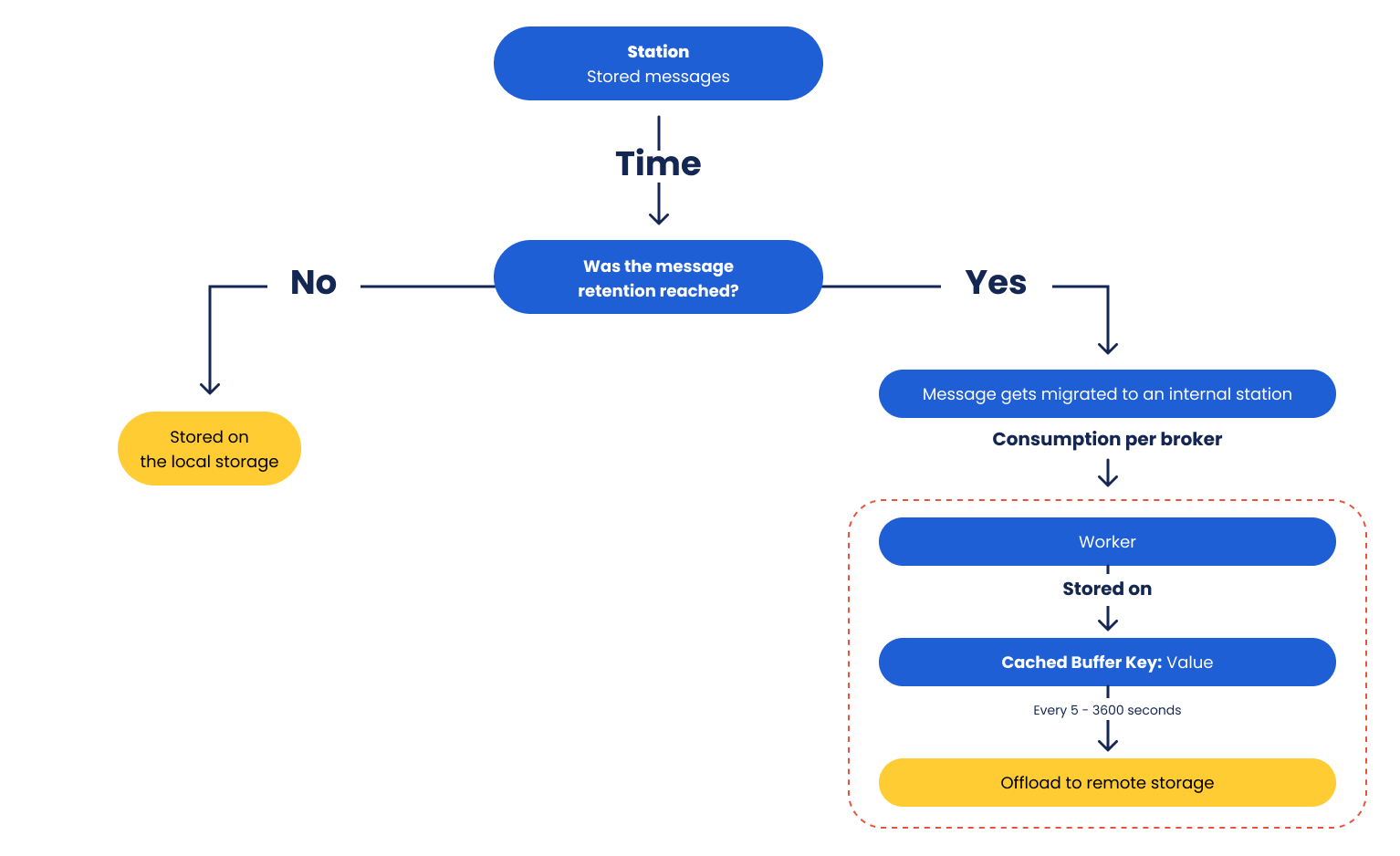
Storage tiering is an excellent capability to separate hot and cold data into different storage classes. Hot data is usually defined as short-term writing and reading, and therefore, data itself should be stored as close as possible to the serving server. In contrast, cold data by definition, is a type of data that will seldom be accessed and can be stored remotely in a slower, less robust storage system, making it a less expensive storage option.
With streaming and traditional streaming engines or platforms, enabling storage tiering means offloading or migrating out-of-retention messages to a second storage class for further archival and processing.
Memphis.dev Open-source version offers this feature out-of-the-box. Memphis storage tiering can be integrated with any S3-compatible object storage and offload out-of-retention data from the local, hot storage to the remote, cold storage, and vice-versa.
By automatically offloading “cold” data to a remote archive, the usage in the local and the much more expensive storage type will be reduced significantly, helping to shrink retention and, with a minimal effort, code and infrastructure-wise – become much more cost-efficient.
Take the following example:
- One company writes 1 TB of data daily.
- Some process functionality over the data occurs on the same day or simultaneously during writing, and some takes place the next day.
- To support both cases, retention has been set to 3 days, so we allocate 3 TBs on a local disk at any given time.
- With storage tiering in place, only 1 TB would ultimately be allocated with an extra two TB on the remote object storage.
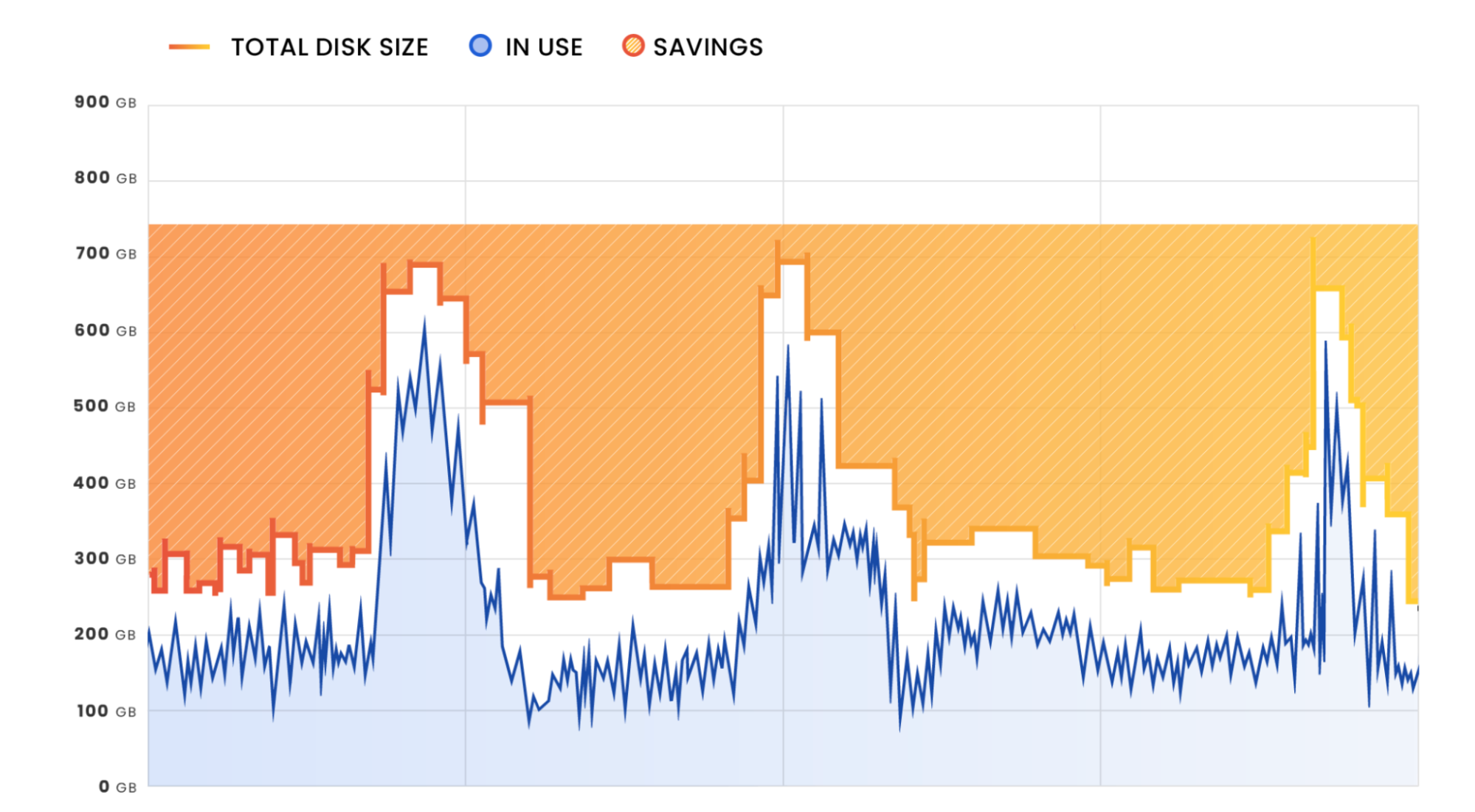
When Kubernetes is used to orchestrate data streaming workloads with high data ingestion requirements, it can potentially overwhelm standard block storage volumes. In such cases, applications may experience severe slowdowns or data loss due to “out of disk errors”, negatively impacting the user experience. This process requires constant monitoring of the volume to ensure sufficient space, as insufficient disk space can compromise the stability of running workloads. The challenge becomes more problematic in cloud environments with hundreds of running pods, which is common for many applications.
To avoid this scenario, engineers often over-provision volumes to ensure they have enough capacity to accommodate fluctuating workloads. However, this practice can get expensive, especially in scenarios where a significant amount of disk space is going unused.
To address these challenges, Zesty Disk for Kubernetes was developed, providing greater elasticity and scalability for Kubernetes environments.
Zesty Disk automatically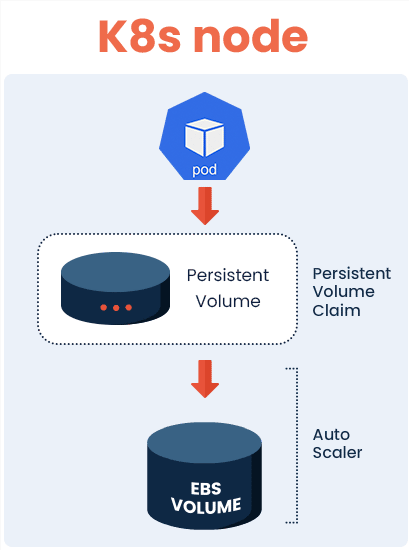 scales EBS disk storage, enabling volumes to automatically expand and shrink based on real-time application needs. This eliminates the need to excessively over-provision storage or to roughly predict volume sizes.
scales EBS disk storage, enabling volumes to automatically expand and shrink based on real-time application needs. This eliminates the need to excessively over-provision storage or to roughly predict volume sizes.
Integrated into the Persistent Volumes of the Kubernetes cluster, Zesty Disk is a virtual filesystem it is able to decouple a large file system volume into multiple volumes that can be elastically added or removed without requiring any down time or disrupting the running pods. This makes Zesty Disk suitable for various Kubernetes workloads, whether they involve simple tasks or intense and dynamic disk usage scenarios, such as data streaming.
The automatic scaling of block storage ensures that the user is matching their provisioned storage as closely as possible to their used storage. Saving significantly on no longer paying for storage that never gets used.
The expansion of volumes ensures that sudden data influxes do not impact container stability potentially causing downtime . While the automatic reduction of volume size saves money by eliminating the need to over-provision excess file system capacity and allowing for downscaling after a significant data influx.
Related Articles
-
 How we maintain Savings Plans coverage at 99% as workloads keep growing
How we maintain Savings Plans coverage at 99% as workloads keep growing
March 26, 2026 -
 Key takeaways from the MarketsandMarkets Cloud FinOps report
Key takeaways from the MarketsandMarkets Cloud FinOps report
February 5, 2026 -
 Accelerating K8s node drains: How we reduced drain time at Zesty
Accelerating K8s node drains: How we reduced drain time at Zesty
January 8, 2026 -
 How we stopped manual pod tuning and shrunk our Kubernetes clusters by 43%
How we stopped manual pod tuning and shrunk our Kubernetes clusters by 43%
December 31, 2025 -
 How we cut EC2 costs by 40% while staying fully flexible
How we cut EC2 costs by 40% while staying fully flexible
December 16, 2025



