
How to Master Databases to Get More from Your Kubernetes Clusters

Sharing the same infrastructure and Kubernetes cluster for stateless applications and databases is tempting, but there are some factors you need to take into account before choosing this route. We’ve already discussed the Kubernetes-friendly characteristics your database should have, but there are additional features required.
Google Cloud suggests the following decision tree to choose between running a database on a VM, running a database on Kubernetes, or using a fully managed database service:
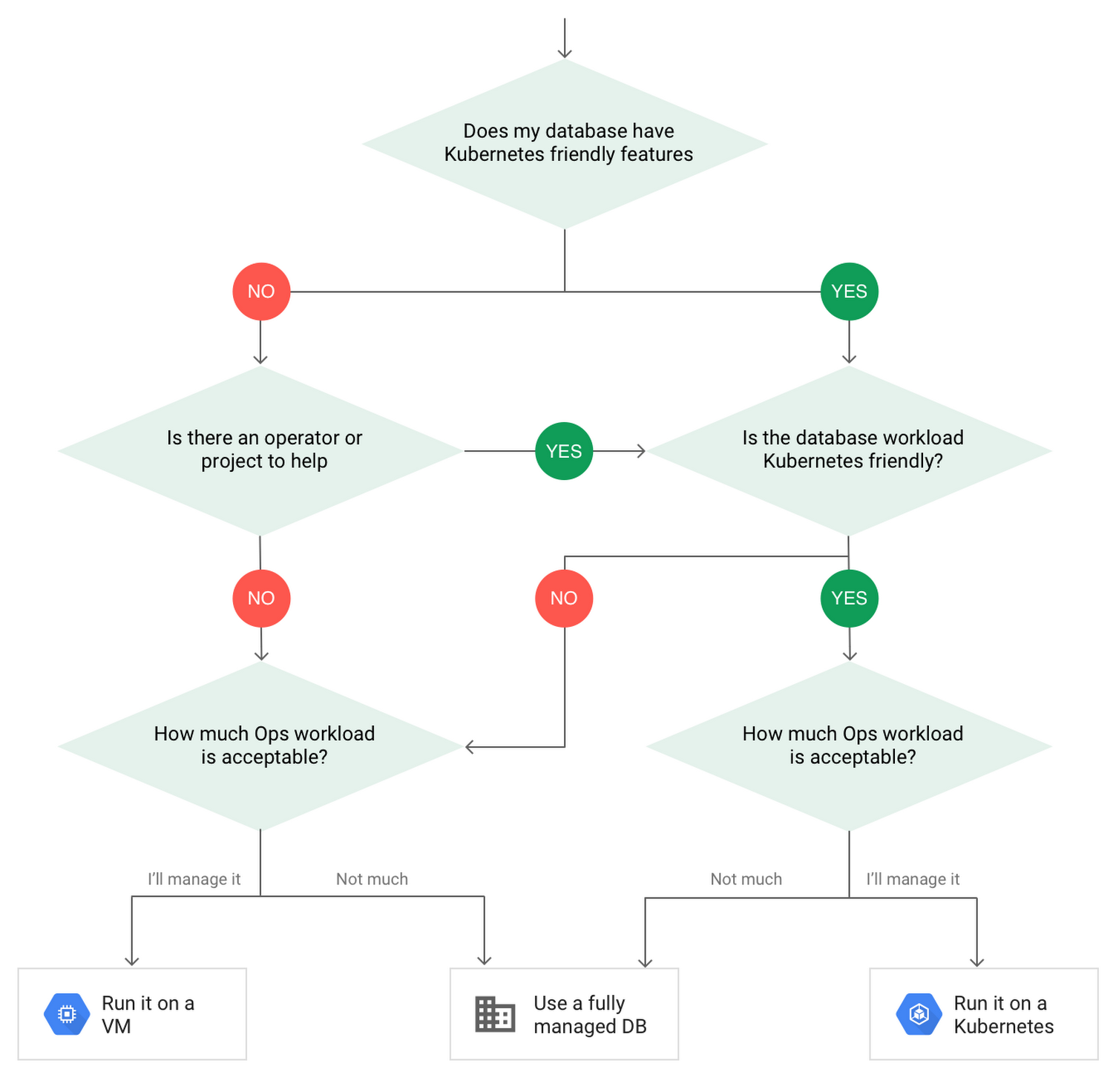
Figure 1: Decision tree for DBs (Source: Google Cloud)
Related Articles
-
 How we maintain Savings Plans coverage at 99% as workloads keep growing
How we maintain Savings Plans coverage at 99% as workloads keep growing
March 26, 2026 -
 Key takeaways from the MarketsandMarkets Cloud FinOps report
Key takeaways from the MarketsandMarkets Cloud FinOps report
February 5, 2026 -
 Accelerating K8s node drains: How we reduced drain time at Zesty
Accelerating K8s node drains: How we reduced drain time at Zesty
January 8, 2026 -
 How we stopped manual pod tuning and shrunk our Kubernetes clusters by 43%
How we stopped manual pod tuning and shrunk our Kubernetes clusters by 43%
December 31, 2025 -
 How we cut EC2 costs by 40% while staying fully flexible
How we cut EC2 costs by 40% while staying fully flexible
December 16, 2025


