

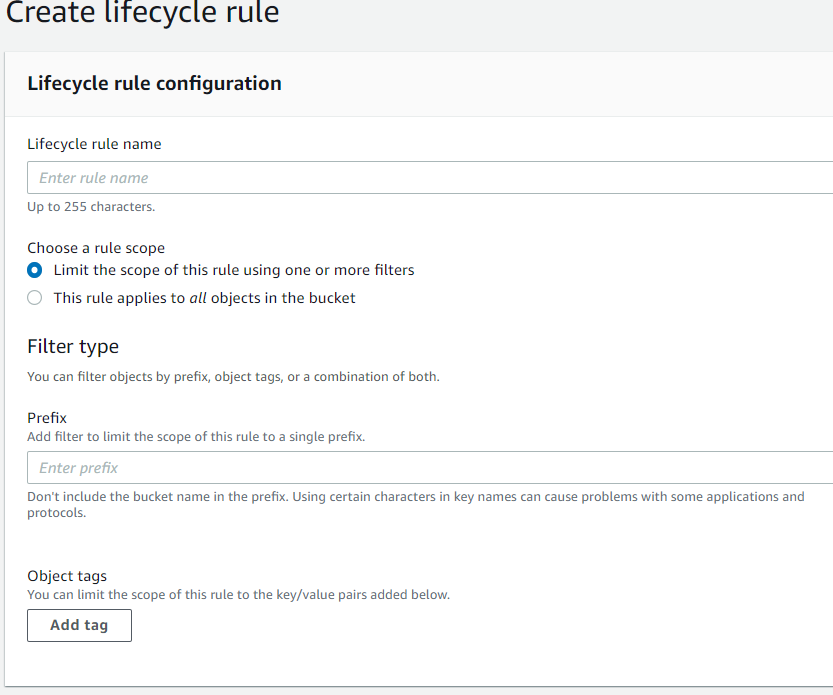
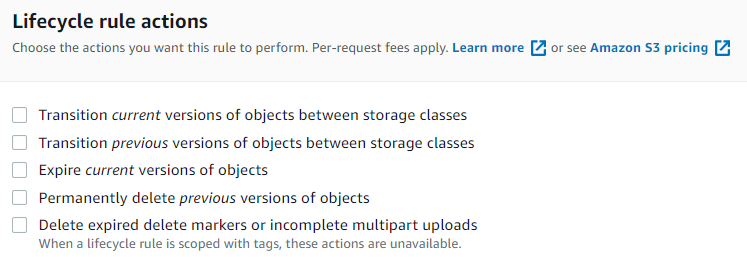
Related Articles
-
 Cloud Updates – September 2024
Cloud Updates – September 2024
October 16, 2024 -
 This is why modern finance professionals must understand Cloud FinOps
This is why modern finance professionals must understand Cloud FinOps
September 19, 2024 -
 Zesty expands Insights with new cost-saving features for AWS services
Zesty expands Insights with new cost-saving features for AWS services
September 17, 2024 -
 Cloud Updates – August 2024
Cloud Updates – August 2024
September 12, 2024 -
 Zesty Disk now optimizes AWS EBS costs across all major operating systems
Zesty Disk now optimizes AWS EBS costs across all major operating systems
August 28, 2024





