
Types of Kubernetes Autoscaling
Kubernetes autoscaling is generally categorized into three main processes: Horizontal Pod Autoscaling (HPA), Vertical Pod Autoscaling (VPA), and Cluster Autoscaling (CA). Each process plays a specific role in managing resources at different levels of the Kubernetes architecture.
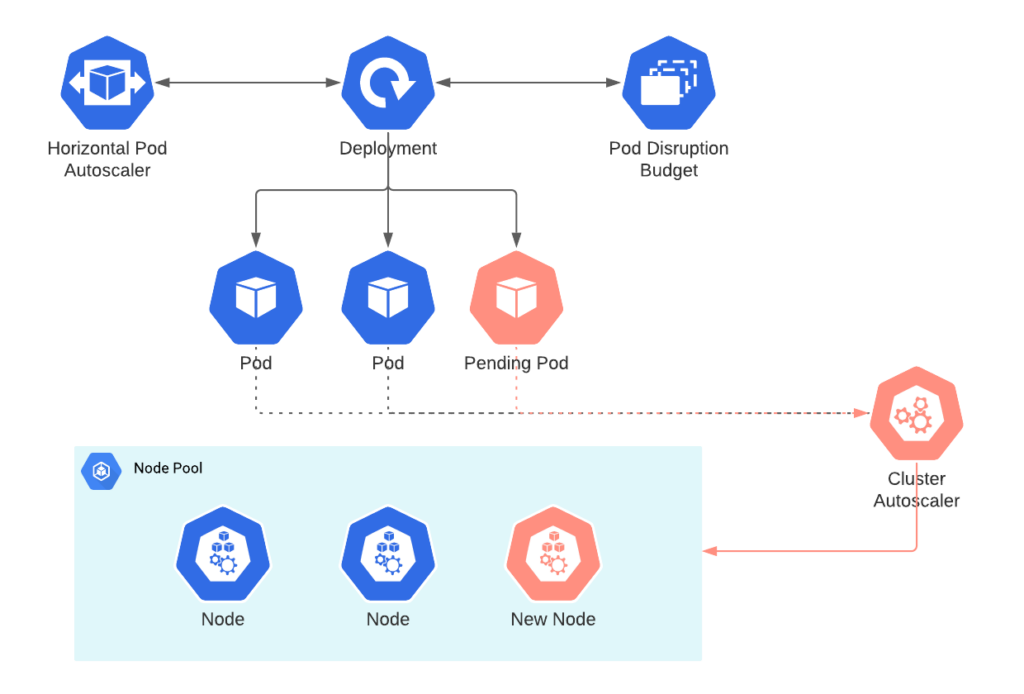
Horizontal Pod Autoscaling (HPA)
HPA adjusts the number of pod replicas within a deployment based on resource utilization, such as CPU or memory. If a workload requires more resources, HPA increases the number of pods. If resources are underutilized, HPA reduces the pod count, ensuring scalability and performance optimization.
Vertical Pod Autoscaling (VPA)
VPA automatically adjusts the resource requests and limits of a pod, scaling its CPU and memory allocations up or down. Instead of increasing or decreasing the number of pods, VPA modifies the resources assigned to individual pods to ensure they can handle changing workloads more effectively.
Cluster Autoscaling (CA)
Cluster Autoscaling focuses on scaling the number of nodes in a Kubernetes cluster. When there is an increase in pod demand and there are not enough resources in the current nodes, CA provisions additional nodes to meet the resource requirements. Similarly, it removes underutilized nodes when the demand decreases, optimizing resource use across the cluster.
Other Scaling Considerations in Kubernetes
In addition to these core processes, there are additional types of scaling mechanisms or strategies that complement the three main processes:
- Node Autoscaling: While technically part of Cluster Autoscaling, some cloud providers offer more granular or specialized node autoscaling mechanisms.
- Autoscaling with Custom Metrics: Kubernetes supports autoscaling based on custom metrics, where you can define application-specific metrics to trigger scaling.
- Job or Task Scaling: Workloads like batch jobs or stateful workloads may have their own scaling triggers, especially for specialized Kubernetes environments such as serverless frameworks (e.g., Knative) or Kubernetes Jobs.
Value Proposition
- Efficiency: Autoscaling helps Kubernetes allocate resources dynamically, ensuring that applications run with the right amount of power without overspending.
- Cost Savings: By scaling resources up or down based on actual demand, organizations avoid over-provisioning, reducing cloud costs.
- Performance Optimization: Ensures that applications can handle fluctuations in traffic or load, improving performance and reliability.
Challenges
- Configuration Complexity: Fine-tuning autoscaling parameters can be complex, requiring careful monitoring and adjustments.
- Latency in Scaling: Autoscaling can introduce a delay in response to spikes in traffic, leading to short-term performance issues.
- Resource Imbalances: Misconfigured autoscaling can lead to resource imbalances, either under-provisioning or over-provisioning resources.
Key Features
- Automatic Resource Management: Adjusts resources in real-time based on workload demands.
- Custom Metrics: Autoscaling can be configured using custom metrics beyond CPU and memory, such as network usage or application-level metrics.
- Integration with Cloud Providers: Most major cloud platforms provide built-in support for Kubernetes autoscaling, enabling seamless resource scaling.
Similar Concepts
- Elastic Scaling: The concept of dynamically adjusting resources to match demand in cloud environments.
- Node uto-provisioning: Automated process that dynamically adds or removes nodes in a Kubernetes cluster based on resource demands, ensuring the cluster has sufficient capacity to run workloads without manual intervention.


