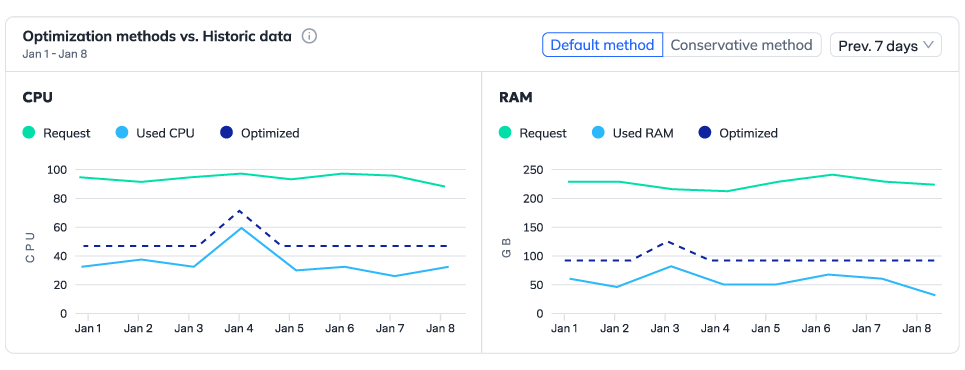
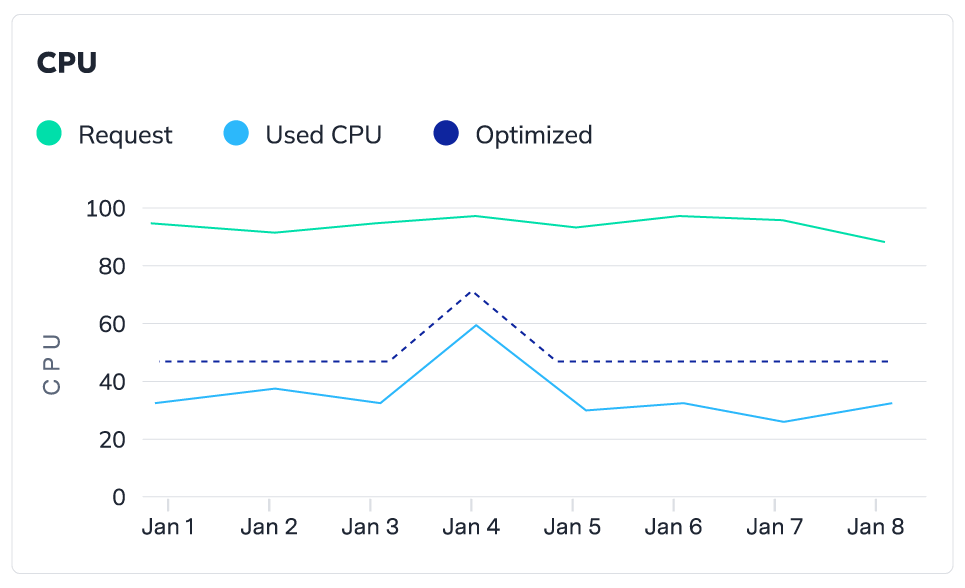
Yes, security is a priority. The platform complies with industry standards, encrypts all data, and offers role-based access controls, ensuring only authorized users can access your Kubernetes cost data and settings. Only meta-data and usage metrics are collected, Zesty doesn’t have access to any data on the disk or the EC2 instance. These metrics are reported to an encrypted endpoint, and sent unidirectionally to Zesty’s backend. All of Zesty’s architecture is serverless meaning there are no servers or databases involved and all data collected resides within AWS.