
6 Simple Ways To Manage S3 Costs

CTO and Co-founder
Amazon S3 is one of the cheapest and most versatile cloud storage mediums available. However, organizations heavily relying on S3 to store, access, or transfer large volumes of data can see their AWS bill quickly going up every month.
Like any cost optimization initiative, reducing S3 costs requires some prior knowledge and planning. This includes understanding the S3 storage classes, its pricing model, and the cost reduction features Amazon offers.
This post is the third and final part of a series of articles we published about Amazon S3. In the second part of this series, we talked about S3 storage tiers and the different cost elements associated with S3. In this article, we will discuss how to minimize those costs.
Tip 1: Choose the Best Storage Class
S3 has a few storage classes, each with a different price tag. The most common and expensive one is the S3 Standard. However, data storage requirements seldom map to any single tier. For example, the latency and throughput needed for operational data in a data lake are not required when storing application log files. Similarly, the durability and availability requirements to host static website contents will not be the same when storing processed output files.
Therefore, the first step in S3 cost-optimization is to identify data that is already stored, data to be stored in the future, and then choosing the right storage class. For example, let’s consider a company that wants to store 1 TB worth of files in the us-east-1 region. The customer will not need to access the data daily.
Using the S3 Standard class to store this data will see the company paying $0.023/GB x 1024 GB = $23.552 per month, or $282.64 per year.
If the company decides to store it in S3 Standard – Infrequent Access tier, the cost will be half: $0.0125/GB x 1024 GB = $12.8 per month, or $153.6 per year.
Tip 2: Store Compressed Data
To further minimize the storage cost, AWS customers can store their data in a compressed format. Usually, file compression is best suited for human-readable text files with whitespaces, like JSON, CSV, XML, or log files. The benefit of compression becomes apparent in large data processing workloads like data lakes or big data analytics where terabytes or petabytes of data are processed every day.
Typical compression formats include gzip, bzip, bzip2, zip, 7z, etc. Each has its compression ratio, and time to decompress. Many applications can also directly read from compressed files, so organizations need to find the best balance between speed and compatibility.
Another way to save storage costs is to store data in columnar format. The most common storage format is Parquet. There are other formats like Avro or ORC. Saving data in a columnar format or compressed form also ensures the number of GET or PUT requests is minimized, reducing the overall cost.
Tip 3: Choose Optimal File Size
For use cases where the data type is relatively well-known, organizations can decide on cost-effective file size. If the workload is primarily read-oriented, it makes sense to save data in multiple smaller files. This ensures each GET operation can quickly complete when reading files. However, this also means a large number of PUT operations to write those files. Similarly, for write-intensive operations, it would be worthwhile to save larger files with few PUT operations. The optimal size is anywhere in between, and it’s often a matter of trial and error.
Tip 4: Partition Files Evenly
SQL queries are often used for reading S3 data. Services like AWS EMR (when using EMRFS), Redshift Spectrum, or Amazon Athena map their tables to underlying S3 buckets and folders. Queries have to scan many files from the target bucket if the data files are not partitioned by a common field like date or time. This can result in a high number of GET requests. To minimize GET operation costs and improve query performance, data in S3 buckets should be partitioned where possible.
Tip 5: Use Lifecycle Policies
S3 lifecycle rules can automatically perform specific actions on S3 files that are older than a certain number of days. The actions are available for all files in a bucket or files with particular prefixes or tags.
Lifecycle actions can be any of the following:
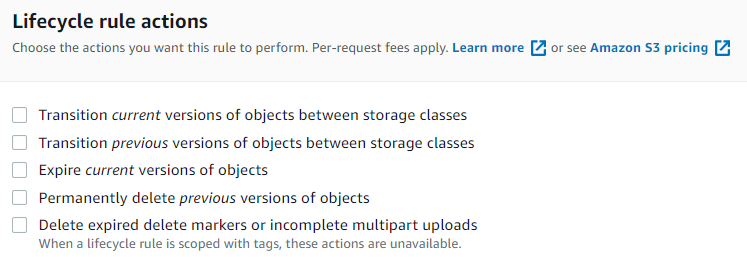
Now, bear in mind, performing some of these actions also costs money. How much money will these actions cost depend on the data volume affected? For example, if a large number of files are already stored in the S3 Standard class before a lifecycle action moves these to Amazon Glacier, the initial cost can be high due to a large number of PUT requests. The same is true when expiring or removing object versions. Solution architects need to choose the appropriate storage class, the number of versions to keep, and the lifecycle’s retention period to minimize such expenses.
It’s also necessary to delete files with no value and with little chance of use. Examples of such files can be old backups, test data, files already loaded into data warehouses, etc.
Tip 6: Minimize Cross-Region Data Transfer
Based on an S3 bucket’s policy, its data can be made accessible from the same or other AWS accounts or even from anywhere in the world. Data transfer into S3 from the Internet is free of charge, but data transfer to the Internet is not. This means there are costs associated with:
- Cross-region replication between S3 buckets
- Cross-region data transfer to EC2, EMR, Redshift, or RDS
- Accessing static website contents hosted in S3
For example, the S3 data transfer rate between the AWS Singapore and Sydney regions is $0.09 per GB. Transferring 50 TBs of S3 data from Singapore to the Sydney region will cost 50 x 1024 x $0.09. = $4,608.
That’s why application architectures should place the S3 buckets and the AWS resources that access those buckets in the same region. Similarly, when serving static contents like images and videos for websites from an S3 bucket, it’s best to use AWS CDN (Content Distribution Network) to cache the data.
Final Thoughts
Reducing S3 costs is often an afterthought for many organizations, partly due to the perception of S3 being a cheap storage medium. While it’s true that S3 expenses may not be as evident as other resources like Redshift of RDS, the footprint can grow over time. Using lifecycle policies, partitioning, or batching similar data operations in groups can minimize that footprint.

Related Articles
-
 Zesty now supports In-Place Pod Resizing for Seamless, Real-Time Vertical Scaling
Zesty now supports In-Place Pod Resizing for Seamless, Real-Time Vertical Scaling
July 30, 2025 -
 Kubernetes Updates – June
Kubernetes Updates – June
July 16, 2025 -
 The endless cycle of manual K8s cost optimization is costing you
The endless cycle of manual K8s cost optimization is costing you
July 2, 2025 -
 Kubernetes Updates – April 2025
Kubernetes Updates – April 2025
May 21, 2025 -
Kubernetes Updates – March 2025
April 23, 2025


