What Does Kube-proxy Do?
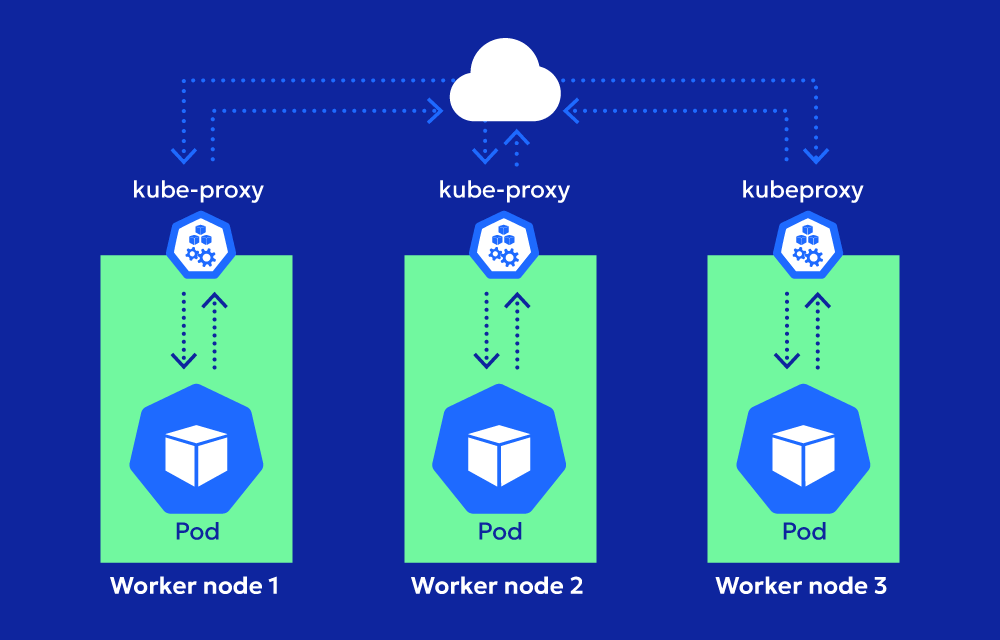
Kube-proxy is all about making sure services in your cluster are accessible and that traffic gets to the right place. Kubernetes services provide an abstraction that allows you to expose a set of pods using a single IP address and port. Kube-proxy is the behind-the-scenes worker that makes this magic happen.
When a service is created, it sets up the necessary network rules to route incoming requests to one of the pods backing the service. This can involve IP tables, IPVS (IP Virtual Server), or other networking mechanisms depending on the configuration. If pods are added or removed from the service, Kube-proxy updates the rules to reflect the changes.
How it Works
Let’s break down the process:
- Service Definition: When you create a Kubernetes service, it defines a virtual IP (ClusterIP) and a set of backend pods that should handle requests.
- Rule Creation: Kube-proxy listens to the Kubernetes API server for service and endpoint changes. When a new service or endpoint is created, it sets up routing rules on the node.
- Routing Traffic: Once the rules are in place, Kube-proxy ensures that any traffic targeting the service’s ClusterIP is forwarded to one of the available pods. It can balance traffic across pods using round-robin or other strategies.
- Dynamic Updates: If a pod backing the service is deleted or a new pod is added, Kube-proxy updates the rules to maintain the service’s availability.
Modes of Operation
Kube-proxy can operate in different modes based on your cluster’s setup:
- Userspace Mode: An older approach where Kube-proxy redirects traffic through userspace. It’s slower because each request passes through the proxy process, but it’s simpler.
- iptables Mode: A faster and more efficient mode that uses Linux’s iptables to route traffic directly to the appropriate pod. This is the most common mode today.
- IPVS Mode: A more advanced mode using IPVS, which provides better performance and scalability than iptables, especially for large clusters.
Key Responsibilities
Load Balancing:
Acts as a built-in load balancer for Kubernetes services. Imagine you have multiple pods handling the same workload. Kube-proxy ensures that incoming traffic is distributed evenly among these pods. It doesn’t just randomly pick a pod—it uses algorithms like round-robin or hashing to decide which pod gets the next request. This ensures no single pod is overwhelmed while others sit idle. It’s like having a traffic cop efficiently directing cars at a busy intersection.
Service Discovery:
Without Kube-proxy, your services would be like unmarked buildings with no address. It makes sure every service has a unique ClusterIP and port, essentially giving it a “directory listing.” When a client queries the service’s IP, Kube-proxy knows exactly where to route the request—even if the pods backing the service are moved or replaced. It’s what makes Kubernetes services easy to find and use, even in the ever-changing landscape of a cluster.
Failover:
Pods aren’t immortal. They crash, get evicted, or are scaled down. Kube-proxy handles these hiccups gracefully. If a pod becomes unavailable, it automatically updates its rules to remove that pod from the list of endpoints. This means client requests never hit a dead end. It’s like a smart GPS that reroutes you instantly when there’s a roadblock, ensuring you always reach your destination without unnecessary delays.
Common Challenges Kube-proxy Handles
Networking in Kubernetes can present some unique challenges. Let’s dive deeper into the issues and explore how Kube-proxy addresses them:
Large-scale Clusters:
In massive clusters with thousands of services and pods, iptables rules can become incredibly complex and difficult to manage. Each new service or endpoint requires additional rules, and as these grow, they can slow down network performance. This is because iptables processes rules sequentially, and with a large number of entries, latency can creep in. To tackle this, Kubernetes offers the IPVS mode as an alternative. IPVS uses hashing and a kernel-based approach to handle routing, making it significantly faster and more scalable for large environments.
Network Overhead:
Inefficient routing or misconfigured services can lead to excessive network hops, causing increased latency and wasted bandwidth. For instance, if a service is accidentally routing traffic across multiple availability zones (AZs) instead of staying within a single AZ, you’re not only adding unnecessary latency but also incurring additional cross-AZ data transfer costs. Kube-proxy helps minimize this by ensuring traffic is directed efficiently based on the rules set in the service configuration, but operators must remain vigilant about service and network designs.
High Traffic Volumes:
When dealing with services that experience high traffic spikes, like during peak hours or major events, Kube-proxy must scale effectively to maintain performance. However, iptables’ sequential processing can become a bottleneck under heavy loads. Switching to IPVS mode is often the solution here, as it handles large volumes of concurrent connections far more gracefully. Additionally, ensuring the underlying node’s resources—such as CPU and memory—are sufficient for Kube-proxy’s operations is critical.
Dynamic Environments:
Kubernetes clusters are highly dynamic by nature. Pods come and go frequently, and services may need to adapt on the fly. Kube-proxy ensures that network rules stay up-to-date, but in highly volatile environments, the constant churn can still lead to temporary inconsistencies. Operators need to carefully monitor and tune the cluster to prevent disruptions during high pod turnover or node failures.
Performance Monitoring:
Diagnosing network performance issues can be challenging. Debugging problems like packet drops or slow responses often requires examining both Kube-proxy logs and the underlying network infrastructure. Tools like Kubernetes’ built-in diagnostics, along with third-party monitoring solutions, are invaluable in these scenarios.
Troubleshooting
When things go wrong, here’s where to start:
- Service Unreachable: Check if the service’s ClusterIP is correct and ensure pods are healthy.
- Connection Errors: Verify that Kube-proxy is running on the node and that the network rules are correctly set up.
- Performance Issues: Consider switching from iptables to IPVS for better handling of large numbers of services and endpoints.
Why Is it essential for networking?
Without Kube-proxy, Kubernetes networking simply wouldn’t work. It’s the glue that connects services to pods, ensuring that traffic flows correctly even as the cluster scales and changes. Whether you’re deploying a small test cluster or running a massive production environment, Kube-proxy ensures that your applications are reachable and performant.
References
- Kubernetes Documentation: Kube-proxy


