
Understanding AWS compute waste and how to prevent it

AWS compute waste remains a significant challenge for the cloud industry. In 2023, the annual public cloud service spending was approximately $563.6 billion, with a staggering 28% of that amount, or approximately $157 billion, being wasted according to the 2024 State of Cloud report by Flexera. Furthermore, the very recent 2024 State of FinOps data report emphasizes that reducing cloud waste and managing unused commitments have become top concerns for all the surveyed organizations.
Thus, understanding the root causes of AWS compute waste and optimizing for prevention is not just beneficial; it has become essential. This blog will guide you through the basics of AWS compute waste, explore the reasons behind it, and share proven strategies to prevent it. Read on to align with the latest FinOps trends!
Understanding the Reasons Behind AWS Compute Waste!
At its core, AWS compute waste refers to the resources that are paid for, but not efficiently utilized. This inefficiency can stem from several key factors, each contributing to a financial strain on organizations. Some of the primary factors are:
- Volatility and Predictability Challenges: The dynamic nature of both internal and external environments complicates the task of accurately predicting workload demands. External factors, such as technological advancements or geopolitical events, can rapidly alter a product’s relevance or unexpectedly increase demand. The COVID-19 pandemic serves as a prime example of how external events can significantly impact demand.Similarly, internal shifts in strategic direction or product development can abruptly change workload requirements. Consequently, these unpredictable factors necessitate a cautious approach from organizations, often leading to overprovisioning as a protective buffer against unforeseen demand fluctuations.
- Caution and Overprovisioning: In an effort to ensure availability and performance, companies often err on the side of caution, provisioning more resources than necessary. This safety measure, while understandable, results in significant waste as these additional resources frequently remain underutilized.
- Commitment Plan Constraints: Commitment plans, such as 1-3 Year Reserved Instances or Savings Plans, are agreements where organizations commit to using a certain amount of cloud resources over a specified period in exchange for lower prices. However, these plans carry the risk of overprovisioning due to limited visibility into future usage, ultimately leading organizations to waste more than they intended to save from discounts.
- Inefficient Resource Allocation: Inefficient resource allocation plays a crucial role in contributing to AWS compute waste. This occurs when resources are not optimally assigned according to workload demands, resulting in surplus resources in some areas and shortages in others. While surplus resources represent a clear waste, shortages present a subtler form of waste.In cases of insufficient provisioning, organizations are forced to rely on more expensive On-Demand resources instead of utilizing discounted options available through commitment plans. This not only leads to higher costs but also highlights the inefficiencies in resource allocation and commitment plan usage, increasing the overall waste of money.
- Complexity of Managing EC2 Resources: The management of EC2 resources has grown increasingly complex with the wide range of options available. Beyond on-demand resources, AWS offers commitment plans like Reserved Instances and Savings Plans. Furthermore, each option comes with its own set of characteristics and features, offering flexibility in some areas like operating systems or regions while being restrictive in others. Understanding this complexity to efficiently manage EC2 resources is in itself a significant challenge, contributing to compute waste.
How to Prevent AWS Compute Waste through Optimum Utilization of Resources?
While there are numerous approaches to mitigating AWS compute waste—ranging from rightsizing instances, scheduling start-stop times for non-critical workloads, to employing auto-scaling policies—the most effective strategy zeroes in on the core issue: optimizing resource utilization. While maintaining efficiency in resource utilization is incredibly hard because of the complexity involved, tools like Zesty’s Commitment Manager can help. Its machine learning algorithm optimizes the allocation and utilization of cloud resources to match your workloads’ actual demand.
Focusing on resource utilization, Zesty’s Commitment Manager strategically employs a blend of Convertible Reserved Instances (CRIs) and Savings Plans (SPs). This combination allows for flexible, cost-efficient management of cloud resources, catering to both predictable and variable workloads.
- Convertible Reserved Instances (CRIs) are particularly valuable for dynamic workloads with fluctuating demands. They offer the flexibility to change instance types, operating systems, and tenancies, ensuring that you can adapt to changes without losing the financial benefits of reserved instances. While CRIs offer discounts of up to 66%, the adaptability they offer is crucial for managing volatile workloads effectively, directly addressing compute waste by avoiding overprovisioning and underutilization.
- Savings Plans (SPs) complement this approach by offering a more predictable cost-saving mechanism for stable, consistent workloads. With discounts varying from up to 66% to up to 72% compared to on-demand rates, SPs require a 1-3 year commitment to a consistent usage amount, measured in $/hour payment. As the hourly payment remains the same irrespective of actual usage, this model is ideal for workloads with predictable demands, providing substantial savings while simplifying budgeting and financial planning.
- Standard Reserved Instances (SRIs) are an effective cost-saving strategy for users with steady-state workloads. By offering a significant discount of up to 75% compared to on-demand pricing, SRIs require a commitment to a specific instance type in a particular region for a term of either 1 or 3 years. However, unlike Convertible Reserved Instances (CRIs), SRIs offer less flexibility in terms of changing instance types, operating systems, or tenancies after purchase. This makes SRIs best suited for applications with predictable usage patterns, where the workload requirements are well-understood and stable over time, ensuring that the capacity is fully utilized throughout the term of the reservation.
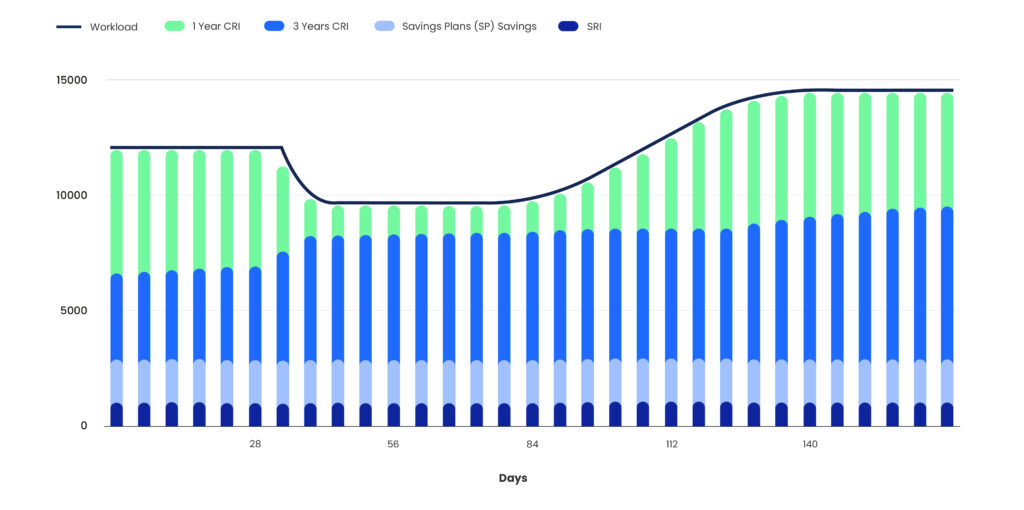
For example, in the above image, Zesty’s Commitment Manager ensures that stable workloads are covered with SRIs or Savings Plans to secure higher discounts, while the variable demands are efficiently managed through a mix of 1-year and 3-year Convertible RIs. This enables the flexibility to utilize resources as needed without wasting any during low demand periods.
Zesty facilitates workload drop tolerance management and enhances scaling capabilities as needed. It automatically adjusts commitments to match the environment’s needs, ensuring efficient discount allocation across workloads. It enables you to enhance your cloud usage flexibility, ultimately paving the way for optimum resource utilization and reduced cloud waste.
With Zesty, businesses can effortlessly streamline cloud management and mitigate the financial risk of purchasing one or three-year commitments. It also ensures tangible savings, making Zesty’s Commitment Manager an essential asset for cloud cost management.
Explore more details about Zesty’s Commitment Manager or book a demo now!
Related Articles
-
 Why it’s time to get off the manual Kubernetes optimization treadmill
Why it’s time to get off the manual Kubernetes optimization treadmill
August 14, 2025 -
 Zesty now supports In-Place Pod Resizing for Seamless, Real-Time Vertical Scaling
Zesty now supports In-Place Pod Resizing for Seamless, Real-Time Vertical Scaling
July 30, 2025 -
 Kubernetes Updates – June
Kubernetes Updates – June
July 16, 2025 -
 The endless cycle of manual K8s cost optimization is costing you
The endless cycle of manual K8s cost optimization is costing you
July 2, 2025 -
 This is the #1 cloud budget killer (and it’s easier to fix than you think)
This is the #1 cloud budget killer (and it’s easier to fix than you think)
June 16, 2025


