
Introduction
Unlike standard container runtimes (like Docker’s runc) which run containers directly on the host kernel, gVisor runs containers on a user-space kernel – offering many of the security benefits of virtual machines but with lighter weight and faster startup. This article provides a developer-focused overview of gVisor in Kubernetes, including how it works, its architecture, security model, integration with Kubernetes, typical use cases, limitations, and comparisons to other sandboxed runtimes such as Kata Containers and Firecracker.
What is gVisor?
gVisor is often described as an “application kernel” for containers. It implements a large portion of the Linux system call interface in a memory-safe, user-space program (written in Go). In essence, gVisor inserts a special layer between the application in a container and the host kernel. Instead of the application invoking system calls directly on the host’s Linux kernel, those calls are intercepted and handled by gVisor’s own kernel code running in user space. This design means the container processes interact with a Linux-like kernel provided by gVisor (sometimes called the gVisor “sentry”) rather than the real host kernel.
By doing so, gVisor significantly reduces the host’s attack surface. A malicious or compromised application would have to break out of gVisor’s user-space kernel (which is heavily constrained and audited) before it could even attempt to exploit the real host kernel.
The gVisor “sentry” process implements most Linux system calls and resources (like file systems, network, and process management) in Go, which helps prevent common memory safety vulnerabilities. Any system calls that the sentry itself needs to make to the host are minimized and filtered for safety. Overall, gVisor provides an extra security boundary: the host kernel is protected by a user space kernel that is independent from the host and designed for isolation.
How gVisor Works: Architecture and Security Model
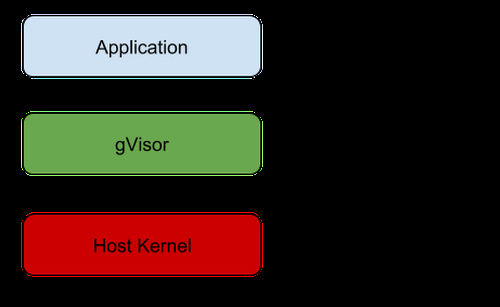
Figure: gVisor’s architecture places a user-space kernel between the application and the host kernel, intercepting system calls to enforce isolation.
Under the hood, gVisor runs each sandboxed container with its own instance of a user-space kernel. This instance intercepts all system calls made by the application and handles them in user space, as if it were the kernel for that application. From the application’s perspective, it behaves like it’s running on a normal Linux kernel (with some limitations discussed later), but in reality those kernel interactions are being emulated by gVisor.
This approach is neither a traditional seccomp/apparmor style filter nor a full VM hypervisor – it’s a hybrid. Traditional container isolation relies on Linux kernel features (namespaces, cgroups, seccomp filters, etc.) to restrict what a container can do. By contrast, gVisor shifts the implementation of the Linux API into user space, creating what’s often called a “sandboxed” container. The architecture can be thought of as a merged guest kernel and hypervisor running as a normal process. There is no separate guest OS; gVisor itself acts as the guest kernel. This yields a smaller resource footprint and faster startup than spinning up a full VM for each container. In fact, gVisor retains a process-like model for resource usage – it doesn’t pre-allocate a large chunk of memory or CPU for a VM, it just uses what the application needs, growing or shrinking like a regular process would.
To intercept system calls, gVisor historically used the Linux ptrace mechanism (similar to how a debugger intercepts syscalls). Newer versions use a more efficient technique called “systrap” (seccomp trap) as the default platform, which triggers a signal on system calls to bounce control to gVisor’s handler. There’s also a KVM-based mode where gVisor leverages hardware virtualization features to speed up context switching, effectively letting the gVisor “sentry” act as both a guest kernel and VMM on real hardware. The KVM mode improves performance on bare metal by using CPU virtualization extensions, while the default mode (systrap) works well even in environments without virtualization (or inside virtual machines). In either case, the container’s threads are confined such that they cannot directly execute privileged instructions or host syscalls – any attempt to do so is caught by gVisor, which then emulates the effect of the syscall in a safe manner.
From a security model perspective, gVisor’s goal is to prevent container escapes by isolating the kernel interface. By providing its own implementation of Linux system calls, gVisor defends against entire classes of kernel vulnerabilities. Even if the application tries to exploit a bug in the kernel API, it’s hitting gVisor’s code, not the host kernel. gVisor’s code is written in Go and designed with memory safety and minimal privileges, making it harder to exploit. Additionally, gVisor employs defense-in-depth: it can use seccomp itself to restrict what the gVisor process can do on the host, and it drops unnecessary privileges, etc., to minimize the impact if someone did manage to compromise the gVisor layer.
It’s important to note that gVisor is not a complete Linux kernel – it supports a broad subset of Linux system calls (over 200 calls implemented) but not every single feature. This sandbox approach comes with some trade-offs in performance and compatibility, which we will explore in later sections.
Integration with Kubernetes
Kubernetes supports gVisor as a sandboxed runtime through the standard Container Runtime Interface (CRI). Practically, this means that instead of using the default runc runtime to run containers, you can configure your cluster to use gVisor’s runtime (runsc) for certain pods. The integration is designed to be seamless: gVisor’s runsc is an Open Container Initiative (OCI) compliant runtime just like runc, so it plugs into Kubernetes via CRI implementations such as containerd or CRI-O. In fact, the gVisor runtime is interchangeable with runc – it can be installed on a node and invoked in place of runc when starting containers.
RuntimeClass mechanism:
Kubernetes provides a feature called RuntimeClass to select the container runtime for pods. By creating a RuntimeClass object that references gVisor (via the handler name runsc), you can decide on a per-pod basis whether to run it under gVisor. For example, one can define a RuntimeClass YAML as follows:
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: gvisor # name of this class
handler: runsc # refers to the gVisor OCI runtime on nodes
In this spec, handler: runsc tells Kubernetes to use the gVisor runtime. Once this class is created (e.g. kubectl apply -f runtimeclass-gvisor.yaml), pods can request it by adding runtimeClassName: gvisor in their Pod spec. Here’s a snippet of a Pod manifest using gVisor:
apiVersion: v1
kind: Pod
metadata:
name: example-gvisor-pod
spec:
runtimeClassName: gvisor
containers:
- name: app
image: alpine:latest
command: ["echo", "Hello from gVisor"]
When such a pod is scheduled, the Kubernetes kubelet on the node sees the runtimeClassName: gvisor and will invoke the CRI to run the container with runsc instead of the default runtime. This requires that the node’s CRI runtime is configured to know about runsc. For instance, if using containerd, you need to update its configuration to add a runtime handler for “runsc”. In containerd’s /etc/containerd/config.toml, this might look like:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runsc]
runtime_type = "io.containerd.runsc.v1"
This registers runsc as a valid runtime. With that in place (and the runsc binary installed on the node), Kubernetes can launch pods with gVisor easily. If using CRI-O, a similar configuration is done to add a runtime class for gVisor.
Managed Kubernetes support:
Many Kubernetes environments make using gVisor even easier. Google Kubernetes Engine (GKE) offers GKE Sandbox, which is essentially gVisor integrated out-of-the-box – you enable it on a node pool, and any pod with runtimeClassName: gvisor (or a specific annotation in older versions) will run in the gVisor sandbox. This is a convenient way to use gVisor in production on GKE with minimal setup. Similarly, Minikube (a local K8s for development) has a built-in addon for gVisor. By running minikube addons enable gvisor, Minikube will install gVisor and create a RuntimeClass for you, so you can try out sandboxed containers locally.
From Kubernetes’ perspective, pods running under gVisor are still normal pods – the difference is purely at the runtime level. The isolation mostly happens inside the node. Networking, scheduling, and other K8s features behave the same, except that gVisor incurs a bit more overhead in the node’s operations. Kubernetes treats the pod as the sandbox boundary, meaning typically the entire pod (all its containers) are placed in a single gVisor sandbox for efficiency and to preserve intra-pod Linux semantics (like shared IPC and loopback networking). This makes gVisor a natural fit for multi-container pods as well, ensuring all containers in the pod are isolated from the host in one sandbox.
Typical Use Cases for gVisor
The primary motivation for gVisor is to run untrusted or less-trusted workloads with a much stronger isolation guarantee than standard containers. Common use cases include:
- Multi-Tenant Platforms: If you run a Platform-as-a-Service (PaaS) or Software-as-a-Service (SaaS) where customers can deploy arbitrary containerized code, gVisor helps ensure that one tenant’s container cannot escape and affect the host or other tenants. For example, Google Cloud Run (a serverless container platform) has used gVisor under the hood to sandbox user containers, and GKE’s sandbox feature is recommended for untrusted code. This allows cloud providers or SaaS companies to execute user-submitted code with an extra layer of security.
- Defense-in-Depth for Sensitive Workloads: Even if you trust your container code, you might use gVisor to add an extra security boundary around particularly sensitive services. If a container running a critical service is compromised, gVisor can limit the impact by preventing kernel-level exploits. This is useful in high-security environments where you assume attackers might find a way to run code in a container, so you sandbox it to protect the infrastructure.
- Running Third-Party or Legacy Software: Sometimes you need to run software of unknown quality (e.g., a third-party binary, plugins, or legacy code) in your cluster. gVisor can sandbox such software to prevent it from using any unexpected kernel mechanisms to compromise the system. It’s like running the software in a lightweight VM, without managing a full VM lifecycle.
- CI/CD and Testing Environments: Continuous integration systems often spin up containers to run untrusted build and test code. gVisor is a good fit here – it can isolate build jobs from the host, reducing the risk from malicious or buggy build scripts. The overhead might be acceptable in exchange for not having to dedicate a full VM per job.
In general, gVisor is most attractive when security isolation trumps raw performance. It shines in scenarios where container escapes must be prevented (or compliance requires strong isolation), and a slight drop in performance or increased complexity is acceptable.
Limitations and Trade-Offs
While gVisor provides valuable security benefits, it’s not a silver bullet. Developers and cluster operators should be aware of the following limitations and trade-offs before choosing gVisor:
- Performance Overhead: Because every system call from the application is intercepted and handled in user space, gVisor inevitably adds overhead. Workloads that are heavy on system calls (e.g. intensive I/O operations, frequent context switches, networking syscalls, etc.) will see the most performance degradation. The overhead can range from negligible (for CPU-bound workloads with few syscalls) to significantly noticeable (for syscall-heavy workloads). Google’s engineers have worked to optimize gVisor – for instance, by moving from ptrace to seccomp trap, and adding KVM support, they reduced context switch costs. In fact, one large-scale user reported that a majority of their applications saw under 3% overhead with gVisor. However, in the worst case, certain applications might run much slower under gVisor than under runc. It’s always recommended to benchmark your specific workload if performance is critical.
- Incomplete System Call Coverage (Compatibility): gVisor does not implement every Linux system call or feature. It targets compatibility with most common APIs, but some syscalls or ioctl calls are unimplemented or only partially supported. Parts of the
/procand/sysfilesystems are also restricted or missing under gVisor. As a result, not every application that runs on Docker will run on gVisor unmodified. In practice, many popular applications do work (e.g. Node.js, Java servers, databases like MySQL, etc., as noted by Google), but if software tries to use a low-level kernel feature that gVisor hasn’t implemented, it may fail with errors like “Bad system call”. For example, some virtualization-related calls, certain kernel tunings, or expecting a specific newer kernel version (gVisor internally reports a Linux 4.4 kernel interface) could cause issues. The gVisor team continues to add support for more syscalls over time, but this gap means gVisor is not 100% drop-in for every workload. - Memory and Resource Overhead: gVisor’s design avoids the large fixed overhead of full VMs – there isn’t a huge memory footprint just to start a sandbox. Nonetheless, running a gVisor sandbox does consume more memory and CPU than a plain runc container. Each sandbox has its own user-space kernel process (the gVisor sentry and associated helper threads), which uses memory for data structures and code. If you run thousands of gVisor-isolated pods, the cumulative overhead in memory might become a factor (though still likely less than thousands of tiny VMs would use). There is also some duplication of work – for instance, file system metadata might be cached by both gVisor and the host, etc. On the flip side, gVisor can more flexibly share resources than a VM – it doesn’t pre-reserve a fixed chunk of RAM for a guest OS, it uses what it needs and returns freed memory to the host. So memory overhead is more dynamic and typically smaller per container than VM-based isolation. It’s a trade-off to consider in capacity planning.
- Requires Maintenance and Updates: Because gVisor essentially re-implements kernel functionality, it needs to be kept up-to-date with security patches and new kernel features. When Linux releases a fix for a critical vulnerability, the equivalent fix may need to be applied in gVisor’s code as well (though the impact might differ). Using gVisor means pulling in another component in your stack that must be monitored for updates. The project is active, but you should plan for testing gVisor updates and integrating them into your nodes regularly, just as you update your base OS or container runtime.
- Debugging and Tooling Considerations: Running a container in gVisor can sometimes complicate debugging. For example, standard tools that expect to interact with the kernel may not behave the same inside a gVisor sandbox. You might see differences in
/procinfo, or certain low-level debugging tools might not work if they rely on unsupported calls. Most normal application-level debugging (logs, core dumps, etc.) still works, but if you’re used to using strace or other kernel interfaces, be prepared for some limitations. Monitoring the performance of gVisor containers might also require using gVisor’s own metrics or observability hooks.
In summary, gVisor trades some performance and compatibility for strong security isolation. These trade-offs mean it’s not ideal for every scenario. High-performance, kernel-intensive workloads (like high-frequency trading systems, or applications that do tons of syscalls) might not be the best fit. But for many common services, the overhead is low enough that the security gains are worth it, especially when dealing with untrusted code.
gVisor vs. Kata Containers vs. Firecracker
Sandboxed container runtimes have a few different approaches. gVisor is one approach; Kata Containers and Firecracker are two other prominent technologies addressing container isolation. Here’s how they compare:
Kata Containers:
Kata Containers run containers inside lightweight virtual machines. When you use Kata, each pod (or container) gets its own mini-VM with a dedicated kernel (often a trimmed-down Linux kernel optimized for containers). Kata is OCI-compliant with a runtime (usually called kata-runtime) that Kubernetes can use similar to gVisormedium.com. The isolation level is very strong – essentially equivalent to a VM per workload – which means the host kernel is almost completely protected (the container talks to a guest kernel, and a hypervisor separates it from the host). Compatibility is generally excellent because the container sees a real Linux kernel (so system calls behave normally, just within the VM)medium.com. The downside is performance overhead and resource footprint: even though Kata’s VMs are lightweight, they still carry the cost of virtualization. There’s extra memory overhead for the guest OS, and interactions have to go through a virtualized layer (virtio devices, etc.). Kata has improved startup times and can use techniques like Kernel Same-Page Merging (KSM) to reduce memory usage, but a Kata container typically has a higher fixed cost than a gVisor container. Kata requires hardware virtualization support (VT-x or AMD-V on the nodes) to run, and in cloud environments you might need to enable nested virtualization if your Kubernetes nodes are themselves VMs. In short, Kata offers strong isolation and compatibility (because it’s real hardware virtualization) at the cost of some efficiency.
Firecracker:
Firecracker is a VMM (Virtual Machine Monitor) originally developed by Amazon for serverless workloads (AWS Lambda and AWS Fargate). It launches micro-VMs that are extremely lightweight: they boot in a fraction of a second and have a minimal device model (only essential devices like virtio-net and virtio-block, no full PC hardware emulation). Firecracker itself is not a complete runtime like runsc or Kata; it doesn’t directly integrate with Docker or Kubernetes out-of-the-box because it isn’t OCI-compliant on its own. However, it can be used under the hood – for example, Kata Containers can be configured to use Firecracker as its hypervisor, or one can use projects like firecracker-containerd to launch Firecracker VMs via containerd. The security isolation of Firecracker is similar to Kata’s approach (each container in a microVM), but Firecracker is tuned for even faster startup and lower overhead. It’s a purpose-built mini-hypervisor that runs a single VM per container, often with a single CPU and a small memory footprint, making it ideal for high density. In practice, Firecracker and Kata solve a similar problem with virtualization; the difference is Firecracker is a lower-level component whereas Kata is a full solution with OCI interface. If we compare to gVisor: Firecracker, like Kata, uses a real Linux kernel for the container (inside the microVM), so compatibility is generally not an issue. Performance can be quite good for many workloads, though any VM-based solution will have some overhead in I/O and CPU due to virtualization. Firecracker’s limitation is that it’s focused on specific use cases (one process per VM, etc.) and currently only supports Linux workloads on x86_64 and aarch64. Also, because it’s not a drop-in runtime, using it in Kubernetes requires more integration effort (often via Kata or custom runtimes).
gVisor vs Other sandbox environments:
Unlike Kata and Firecracker, gVisor does not use hardware virtualization. Its approach is to run containers as normal processes but shield the host kernel by interposing a user-space kernel. This tends to mean gVisor has a smaller memory footprint per container (no guest OS) and can start containers very quickly (no VM boot needed). It also does not require any special CPU support (you can use gVisor even if virtualization is unavailable or in nested cloud environments easily). However, gVisor’s drawback is that it must continuously translate and enforce system calls in software, which can hurt performance for certain workloads. Also, as discussed, gVisor might have compatibility gaps since it’s reimplementing Linux interfaces. Kata, by virtue of using real kernels, often has better compatibility for complex workloads or kernel features. In terms of security, all three (gVisor, Kata, Firecracker) considerably increase isolation compared to vanilla containers. Kata/Firecracker rely on the time-tested isolation of virtualization – even if the container is compromised, breaking out would require a VM breakout (which is very hard). gVisor relies on the isolation of a user-space kernel that’s heavily constrained and isolated from the host – an exploit would require compromising gVisor itself and then the host, which is also a tall order. There isn’t a clear “winner” — the choice often depends on use case:
If you need maximum compatibility and don’t mind the heavier footprint, Kata Containers (or Firecracker via Kata) is a strong choice, as it runs almost anything you throw at it like a normal Linux, just more securely.
If you prioritize minimal resource usage and easier integration and your workloads are within gVisor’s compatibility, gVisor is attractive, especially when you can’t easily use VMs.
Firecracker shines in serverless or function-as-a-service scenarios where you want to pack thousands of microVMs and start/stop them rapidly – it’s a bit specialized, but very powerful in that niche.
In many real-world Kubernetes scenarios, you might see gVisor being used for multi-tenant container security (Google uses it in GKE and Cloud Run), while Kata is used in environments like OpenStack Kata Kubernetes or by cloud providers who favor VM-level isolation (for example, some offerings on IBM Cloud, or Azure’s Kata support for AKS). Firecracker is used by AWS and niche scenarios, and its ideas feed into Kata for broader usage.
Getting Started with gVisor on Kubernetes (Example Configuration)
To illustrate how a developer or operator can enable gVisor in a Kubernetes cluster, let’s walk through a basic setup:
- Install gVisor on each node: Ensure the
runscbinary (gVisor’s runtime) is installed on all Kubernetes worker nodes. You can download it from the gVisor releases. For example: bashCopyEditcurl -Lo runsc https://storage.googleapis.com/gvisor/releases/release/latest/runsc && chmod +x runsc sudo mv runsc /usr/local/bin/This command fetches the latest gVisor binary and makes it executable. Each node’s OS needs to have this available so that the container runtime can invoke it. - Configure the container runtime: If your cluster uses containerd, edit the containerd config to add gVisor. As mentioned earlier, you add a new runtime entry for
runscin/etc/containerd/config.tomlunder thecontainerd.runtimessection. After adding the snippet and reloading containerd, containerd knows about the “runsc” runtime. For CRI-O, you would update its configuration to include an entry for the runtime. (On Docker Engine, you can also use gVisor by specifying--runtime=runscwhen running containers, but Docker alone is not typical in Kubernetes deployments.) - Create the RuntimeClass in Kubernetes: As shown in the YAML example above, create a
RuntimeClassobject named “gvisor” (or any name you choose) and set its handler to “runsc”. This is a one-time (cluster-scoped) setup so that Kubernetes is aware of a runtime option. You can check that the RuntimeClass is created by runningkubectl get runtimeclass. - Schedule pods to use gVisor: Update your Pod specs (or Deployments, etc.) to include
runtimeClassName: gvisorfor any workload you want to sandbox. This can be done selectively – you might tag only certain namespaces or specific pods to use gVisor, depending on your security needs. When these pods start, if everything is configured properly, they will be isolated by gVisor. You can verify by describing the pod (kubectl describe pod) and looking at the runtime used, or checking node logs. Another telltale sign is that inside the pod, the environment will have some differences (for example, certain/procentries might show the kernel as “gVisor”). - Validate functionality: Run your application’s test suite or basic commands in the gVisor-enabled pod to ensure it works as expected. Because gVisor imposes some restrictions, it’s good to verify that your app doesn’t hit an unsupported syscall. If it does, you might need to adjust the app or decide if gVisor is not suitable for that particular workload. For most standard apps, it should work fine.
- Monitoring and debugging: Once running, treat the gVisor pods mostly like any other. You can collect logs and metrics as usual. If you need to monitor gVisor’s performance, gVisor has some integration with tools (e.g., it can expose metrics about the sandbox). In Kubernetes, you should also monitor node resource usage – gVisor will consume CPU for the syscall handling, so if you put many gVisor pods on one node, ensure the node has enough headroom.
Quick alternatives: If the above sounds like a lot of steps, remember that on GKE enabling gVisor is a matter of a checkbox or one command to create a sandbox node pool. On Minikube, it’s similarly easy with an addon. Those are great for experimentation or managed setups. On custom clusters, the manual setup gives you flexibility: you might even configure only specific nodes to support gVisor (so that sensitive workloads schedule there, and others use normal runtime on other nodes). Kubernetes’ scheduling can be tweaked by using labels and a RuntimeClass scheduling field to ensure pods go to nodes that have gVisor. For example, you can taint your gVisor-enabled nodes and set tolerations for pods that require the gVisor runtime class.
Conclusion
gVisor brings an innovative approach to container security in Kubernetes by acting as a lightweight, in-process kernel for containers. It enables organizations to run containers with an extra layer of isolation, defending the host kernel from potential exploits originating in the container. We’ve seen how gVisor integrates with Kubernetes through the RuntimeClass mechanism, making it relatively straightforward to use in modern clusters. Its architecture – a user-space kernel intercepting system calls – offers a compelling middle ground between traditional containers and full virtual machines, with its own pros and cons.
For developers and DevOps engineers, the key takeaways are:
- gVisor can significantly strengthen multi-tenant isolation and is a powerful tool when running untrusted code on Kubernetes.
- It requires mindful setup (installing and configuring the runtime) and an understanding of its limitations (performance and compatibility overheads).
- Alternatives like Kata Containers and Firecracker exist, each with different trade-offs; choosing the right sandbox solution depends on your workload needs for security vs. performance.
- Thanks to its OCI compliance, gVisor has broad compatibility with existing container tooling, meaning you can often adopt it without heavy changes to your workflows.
In an era where cloud security is paramount, gVisor in Kubernetes provides an extra line of defense. By using gVisor thoughtfully – perhaps for the particularly risky parts of your deployment – you can harden your cluster’s security while still benefiting from the efficiency and convenience of containers. With ongoing improvements in gVisor and growing support in the Kubernetes ecosystem, sandboxed containers are becoming an increasingly practical option for production environments that require strong isolation.


