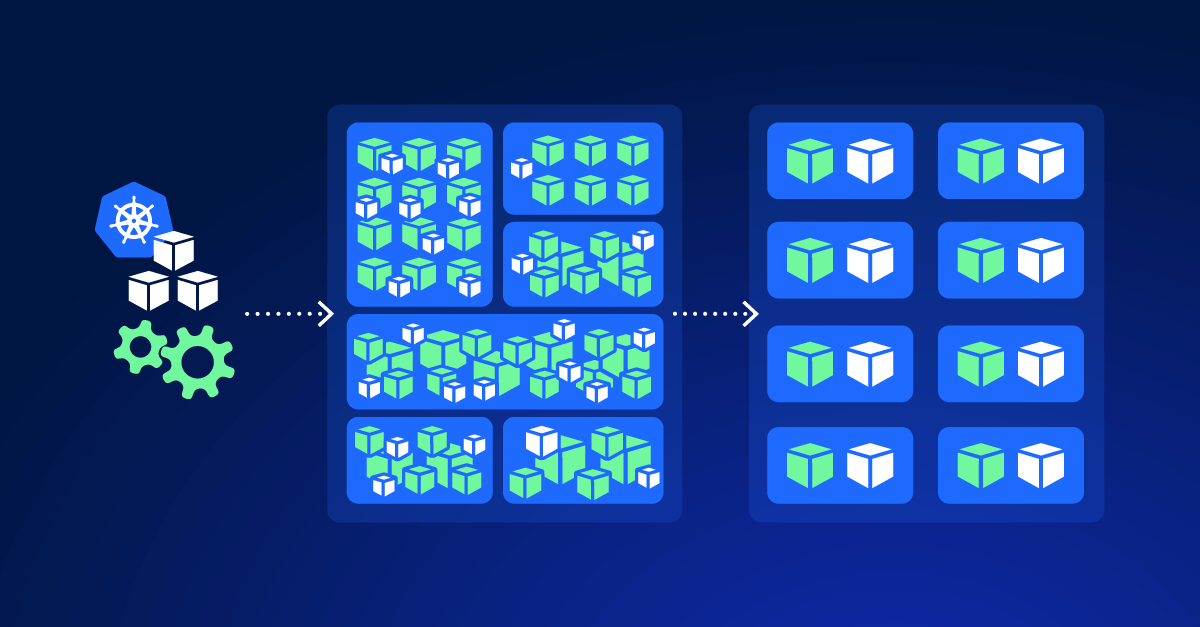
Node overhead can be a significant cost factor in Kubernetes, depending on the scale and configuration of your cluster. Node overhead refers to the resources (CPU, memory, and storage) consumed by the system processes and daemons that are required to run Kubernetes itself, as well as other essential services on each node. These processes include the kubelet, kube-proxy, container runtime, and other system-level services like monitoring agents and network plugins.
Here’s how node overhead can contribute to costs:
Excessive Resource Usage by System Components
- Each Kubernetes node must allocate resources to system components and agents that help manage the cluster. The problem arises when the room taken up by these system processes is either misconfigured or consuming more than necessary. If these agents or components are not optimized, it leads to inefficient use of resources, which can drive up costs.
Scaling Issues and Cost Inefficiency
- In a large-scale environment with many nodes, even a small amount of overhead on each node can add up. For instance, if each node requires an extra 200MB of memory for system components, this overhead could become significant when spread across hundreds or thousands of nodes.
- The solution here is not necessarily to remove these system processes but rather to filter where certain daemons and agents are deployed. By configuring your setup so that only the necessary nodes run certain DaemonSets, you can reduce resource waste without compromising on essential services.
Ways to Reduce Node Overhead and Optimize Costs in Kubernetes
Reducing node overhead in Kubernetes requires a strategic approach to resource management, from selecting the right node instance types to optimizing the configuration of system components. Here’s a more detailed look at each method:
1. Right-Size Node Instances
Choosing the right instance type with the appropriate amount of CPU, memory, and storage is crucial to balancing node overhead and cost-efficiency.
How to Choose the Right Instance Types
- Understand Your Workload Profiles:
- Different applications have different resource demands. Some might be CPU-intensive (e.g., data processing applications), while others may need more memory (e.g., databases). Analyze the resource usage patterns of your workloads to identify the right type of instances.
- For example, if you run primarily CPU-bound workloads, choose instances that offer higher vCPU counts. Conversely, memory-bound applications benefit from instances with larger memory allocations.
- Distribution vs. Centralization:
- Be mindful of the balance between distribution and centralization. Using larger nodes allows for greater efficiency by running more pods per node, but it also centralizes resources. If a large node fails, the impact can be substantial.
- The key is to find the sweet spot: if agents and daemons are substantial enough, they should be part of the logic in determining node size and configuration, ensuring that you are not risking too much centralization.
- Leverage Spot or Preemptible Instances for Cost Savings:
- In cloud environments, consider using Spot Instances (AWS), Preemptible VMs (Google Cloud), or Azure Spot VMs to save costs. These are cheaper but can be terminated with little notice. They are ideal for workloads that can handle interruptions.
- Make sure your Kubernetes setup can handle node terminations gracefully, particularly by using Pod Disruption Budgets (PDBs). PDBs define how many pods can be disrupted during maintenance or scaling events, ensuring that service availability is maintained even when spot instances are terminated. Setting PDBs properly requires understanding your application’s tolerance for disruptions and ensuring the right configurations across your deployments.
2. Optimize DaemonSets
DaemonSets ensure that a copy of a pod runs on every node. While useful, DaemonSets can significantly contribute to node overhead, especially if there are many DaemonSets or if they are not resource-efficient. Unlike core system components, DaemonSets can often be optimized to manage overhead more effectively.
How to Optimize DaemonSets:
- Filter the Nodes Where DaemonSets Run:
- Not all DaemonSets need to be deployed on every node. Configure node selectors and taints/tolerations to limit where DaemonSet pods are deployed. For example, if you only need monitoring on specific nodes, set a node selector to deploy the DaemonSet only on those nodes instead of every node in the cluster.
- This reduces the footprint of DaemonSets and decreases overall node overhead.
- Right-Size DaemonSet Pods:
- Ensure that DaemonSet pods have appropriate resource requests. Unlike core components, there is more flexibility here to monitor actual usage and adjust requests without risking the entire cluster’s stability.
- Optimizing resource requests for DaemonSets ensures they get the right amount of resources, which helps in balancing efficiency and functionality.
- Consolidate Functions When Possible:
- If multiple DaemonSets serve overlapping purposes, consider consolidating their functionality. For example, if two DaemonSets are both handling different aspects of monitoring, find a unified solution that can reduce the number of pods running across your nodes.
By implementing these strategies, you can significantly reduce node overhead in your Kubernetes cluster, leading to better resource efficiency, lower costs, and improved performance across your applications.