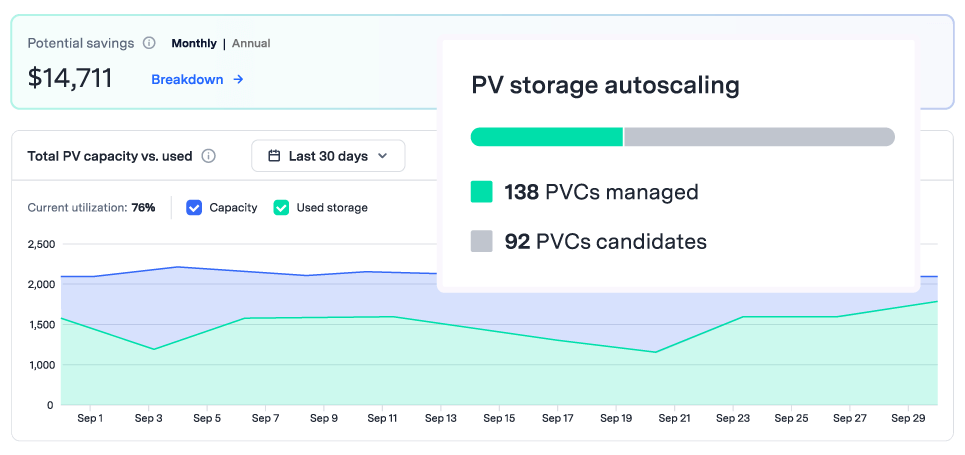
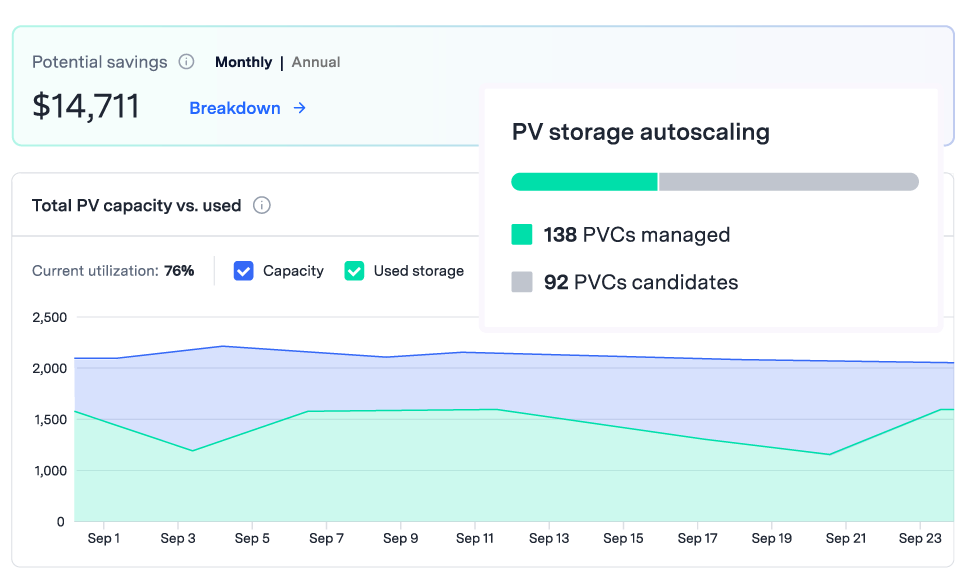
Automatically scale persistent volumes up or down based on real-time usage. Cut idle storage costs by 70% while keeping your applications always available.
To stay resilient during data spikes and avoid late-night fire drills, teams often overprovision persistent volumes. But that safety net comes at a steep cost, typically 3X times more than what’s actually needed. Most of it just sits idle, quietly draining your budget.
Product Capabilities
Fit peaks and dips with real-time PV scaling
Dynamic,
real-time scaling
Rightsize persistent volumes in real-time to align with workload fluctuations and ensure continuous uptime during peak traffic periods.
Downsizing capability
Automatically shrink storage capacity to reduce persistent volume overprovisioning and cut costs.
Precise prediction
models
AI-powered algorithms analyze historical and real-time usage to precisely predict filesystem fluctuations and proactively adjust persistent volumes.
Actionable insights
Gain real-time visibility & insights over your persistent volume utilization. Identify idle resources, overprovisioning, and take action to cut storage costs.
How It Works
Scale up and down, effortlessly
Zesty analyzes real-time usage metrics and metadata to build a live profile of each volume and predict storage needs. It dynamically reshapes the filesystem by attaching or detaching smaller volumes—no downtime, no manual intervention. A built-in buffer ensures enough capacity is always available without overprovisioning.
If you’ve made it this far, these questions are for you
How does the pricing model work?
Our pricing model is designed to be straightforward and transparent. We charge a base fee plus a fee per storage managed by Zesty. Importantly, you’re only billed for the storage capacity managed after optimization. This ensures that you pay only for the resources we actively manage.
Is the platform secure?
Yes, security is a priority. The platform complies with industry standards, encrypts all data, and offers role-based access controls, ensuring only authorized users can access your Kubernetes cost data and settings. Only meta-data and usage metrics are collected, Zesty doesn’t have access to any data on the storage. These metrics are reported to an encrypted endpoint, and sent unidirectionally to Zesty’s backend. All of Zesty’s architecture is serverless meaning there are no servers or databases involved and all data collected resides within AWS.
Will cost optimization impact my applications’ performance?
No, our platform is designed to maintain performance, ensure stability and preserve SLAs, while optimizing costs. Automation keeps storage available when needed, ensuring applications run smoothly even as costs are reduced.
Does it require an agent in order to work?
Zesty requires an agent with read-only permissions to gain visibility into your environment and provide accurate recommendations. For our automated PV Autoscaling solution, an additional agent is needed to enhance efficient automation.
What data sources are used for analysis?
The PV Autoscaling agent collects performance metrics such as disk usage, capacity, IOPS and throughput, and disk metadata such as instance type, disk type, volume names etc.
How long does it take to see savings after implementation?
Users start seeing measurable savings from day one after completing the onboarding process.